
Overview
The Leiden algorithm is a community detection method designed to optimize modularity while addressing some of the limitations of the widely used Louvain algorithm. Unlike Louvain, which may produce poorly connected or even disconnected communities, Leiden guarantees well-connected communities. Additionally, the Leiden algorithm is faster. It is named after the city of Leiden, where it was developed.
References:
- V.A. Traag, L. Waltman, N.J. van Eck, From Louvain to Leiden: guaranteeing well-connected communities (2019)
- V.A. Traag, P. Van Dooren, Y. Nesterov, Narrow scope for resolution-limit-free community detection (2011)
Concepts
Modularity
The concept of modularity, as explained in the Louvain algorithm, is also used in the Leiden algorithm. However, Leiden introduces a new resolution parameter γ (gamma) into the modularity formula:
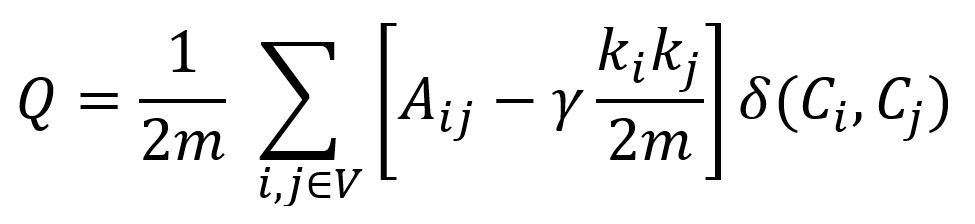
The parameter γ controls the granularity of the detected communities by modulating the balance between intra-community and inter-community connections:
- When
γ> 1, the algorithm favors more and smaller communities that are tightly connected internally. - When 0 <
γ< 1, it favors fewer and larger communities that may be less densely connected internally.
Leiden
When the Leiden algorithm starts, each node is placed in its own community. The algorithm then iteratively proceeds through passes, each consisting of three phases:
First Phase: Fast Modularity Optimization
In the first phase of Louvain, the algorithm repeatedly visits all nodes in the graph until no further node movements can increase the modularity. The Leiden algorithm improves efficiency by only visiting all nodes once initially, and afterwards, only revisiting nodes whose neighborhoods have changed.
To achieve this, the Leiden algorithm maintains a queue, initializes it with all nodes in the graph in a random order, then repeats the following steps until the queue is empty:
- Remove the first node
vfrom the front of the queue. - Reassign node
vto a different communityCthat provides the maximum gain of modularity (ΔQ), or keepvin its current community if there is no positive gain. - If
vis moved to a new communityC, add to the rear of the queue all neighbors ofvthat do not belong toCand that are not already in the queue.
Second Phase: Refinement
This phase produces a refined partition Prefined based on the partition P obtained from the first phase. Initially, Prefined is set as a singleton partition, where each node—either from the original graph or the aggregated graph—is placed in its own community. Then, each community C ∈ P is refined individually as follows:
1. Find each node v ∈ C that is well-connected within C by this formula:
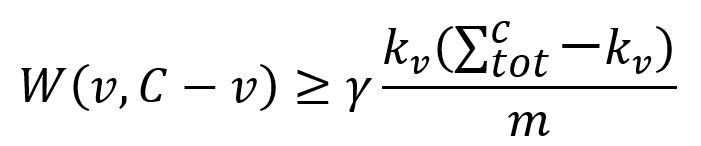
where,
W(v,C-v)is the sum of edge weights between nodevand the other nodes inC.kvis the total edge weights between nodevand the other nodes in the graph.is the sum ofkof all nodes inC.mis the sum of all edge weights in the graph.
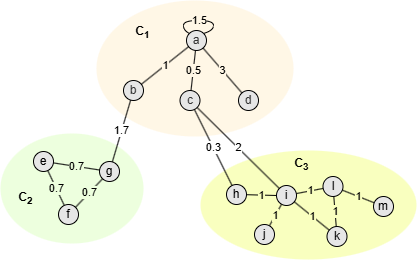
Take community C1 in the graph above as an example, where
- m = 18.1
- = ka + kb + kc + kd = 6 + 2.7 + 2.8 + 3 = 14.5
Set γ as 1.2, then:
- W(a, C1) - γ/m ⋅ ka ⋅ ( - ka) = 4.5 - 1.2/18.1*6*(14.5 - 6) = 1.12
- W(b, C1) - γ/m ⋅ kb ⋅ ( - kb) = 1 - 1.2/18.1*2.7*(14.5 - 2.7) = -1.11
- W(c, C1) - γ/m ⋅ kc ⋅ ( - kc) = 0.5 - 1.2/18.1*2.8*(14.5 - 2.8) = -1.67
- W(d, C1) - γ/m ⋅ kd ⋅ ( - kd) = 3 - 1.2/18.1*3*(14.5 - 3) = 0.71
Therefore, nodes a and d are considered well-connected in C1.
2. Visit each node v. If it remains in its own singleton community in Prefined, randomly merge it into a community C' ∈ Prefined that increases the modularity. The merge is allowed only if C' is well-connected with C, determined by the following condition:
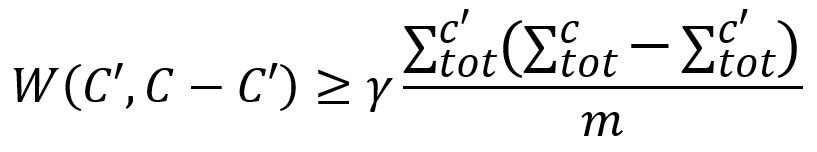
Note that each node v is not necessarily merged greedily with the community that yields the maximum gain of modularity. Instead, the larger the modularity gain, the more likely that community is to be selected. The degree of randomness in selecting a community C' is determined by a parameter θ (theta) as:
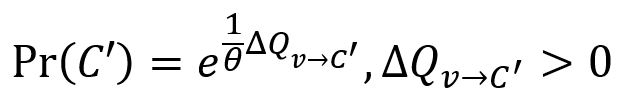
Randomness in the selection of a community allows the partition space to be explored more broadly.
Third Phase: Community Aggregation
The aggregate graph is constructed based on the Prefined obtained from the previous phase. This aggregation process is the same as in Louvain. Note that each node is a single community in the aggregate graph in Louvain. However, the aggregate graph in Leiden is partitioned based on P, so multiple nodes may belong to the same community.
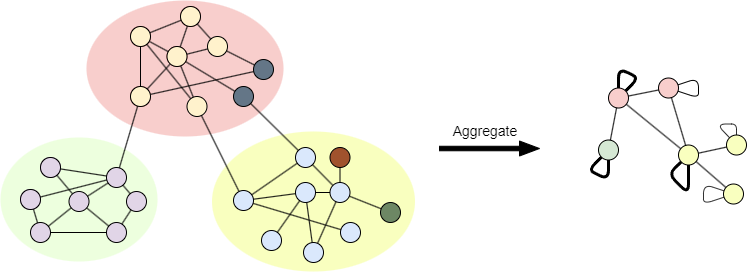
P is denoted by color blocks, Prefined is denoted by node colorsOnce this third phase is completed, another pass is applied to the aggregate graph. These passes are iterated until no further changes occur in the node communities, and the modularity reaches its maximum.
Considerations
- If node
vhas any self-loop, when calculatingkv, the weight of self-loop is counted only once. - The Leiden algorithm treats all edges as undirected, ignoring their original direction.
Example Graph
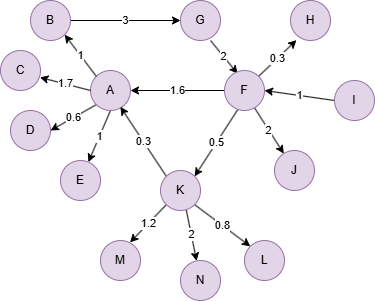
Run the following statements on an empty graph to define its structure and insert data:
ALTER EDGE default ADD PROPERTY {
weight float
};
INSERT (A:default {_id: "A"}),
(B:default {_id: "B"}),
(C:default {_id: "C"}),
(D:default {_id: "D"}),
(E:default {_id: "E"}),
(F:default {_id: "F"}),
(G:default {_id: "G"}),
(H:default {_id: "H"}),
(I:default {_id: "I"}),
(J:default {_id: "J"}),
(K:default {_id: "K"}),
(L:default {_id: "L"}),
(M:default {_id: "M"}),
(N:default {_id: "N"}),
(A)-[:default {weight: 1}]->(B),
(A)-[:default {weight: 1.7}]->(C),
(A)-[:default {weight: 0.6}]->(D),
(A)-[:default {weight: 1}]->(E),
(B)-[:default {weight: 3}]->(G),
(F)-[:default {weight: 1.6}]->(A),
(F)-[:default {weight: 0.3}]->(H),
(F)-[:default {weight: 2}]->(J),
(F)-[:default {weight: 0.5}]->(K),
(G)-[:default {weight: 2}]->(F),
(I)-[:default {weight: 1}]->(F),
(K)-[:default {weight: 0.3}]->(A),
(K)-[:default {weight: 0.8}]->(L),
(K)-[:default {weight: 1.2}]->(M),
(K)-[:default {weight: 2}]->(N);
create().edge_property(@default, "weight", float);
insert().into(@default).nodes([{_id:"A"}, {_id:"B"}, {_id:"C"}, {_id:"D"}, {_id:"E"}, {_id:"F"}, {_id:"G"}, {_id:"H"},{_id:"I"},{_id:"J"},{_id:"K"},{_id:"L"},{_id:"M"},{_id:"N"}]);
insert().into(@default).edges([{_from:"A", _to:"B", weight:1}, {_from:"A", _to:"C", weight:1.7}, {_from:"A", _to:"D", weight:0.6}, {_from:"A", _to:"E", weight:1}, {_from:"B", _to:"G", weight:3}, {_from:"F", _to:"A", weight:1.6}, {_from:"F", _to:"H", weight:0.3}, {_from:"F", _to:"J", weight:2}, {_from:"F", _to:"K", weight:0.5}, {_from:"G", _to:"F", weight:2}, {_from:"I", _to:"F", weight:1}, {_from:"K", _to:"A", weight:0.3}, {_from:"K", _to:"M", weight:1.2}, {_from:"K", _to:"N", weight:2}, {_from:"K", _to:"L", weight:0.8}]);
Creating HDC Graph
To load the entire graph to the HDC server hdc-server-1 as my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
Parameters
Algorithm name: leiden
Name |
Type |
Spec |
Default |
Optional |
Description |
|---|---|---|---|---|---|
phase1_loop_num |
Integer | ≥1 | 5 |
Yes | The maximum number of loops in the first phase during each pass. |
min_modularity_increase |
Float | [0,1] | 0.01 |
Yes | The minimum gain of modularity (ΔQ) to move a node to another community. |
edge_schema_property |
[]"<@schema.?><property>" |
/ | / | Yes | Specifies numeric edge properties used as weights by summing their values. Only properties of numeric type are considered, and edges without these properties are ignored. |
gamma |
Float | >0 | 1 | Yes | The resolution parameter γ. |
theta |
Float | ≥0 | 0.01 | Yes | The parameter θ which controls the degree of randomness during community merging in the second phase; sets to 0 to disable randomness to acquire the maximum gain of modularity (ΔQ). |
return_id_uuid |
String | uuid, id, both |
uuid |
Yes | Includes _uuid, _id, or both to represent nodes in the results. |
limit |
Integer | ≥-1 | -1 |
Yes | Limits the number of results returned. Set to -1 to include all results. |
order |
String | asc, desc |
/ | Yes | Sorts the results by count; this option is only valid in Stream Return when mode is set to 2. |
File Writeback
This algorithm can generate three files:
Spec |
Content |
|---|---|
filename_community_id |
|
filename_ids |
|
filename_num |
|
CALL algo.leiden.write("my_hdc_graph", {
return_id_uuid: "id",
phase1_loop_num: 5,
min_modularity_increase: 0.1,
edge_schema_property: 'weight'
}, {
file: {
filename_community_id: "f1",
filename_ids: "f2",
filename_num: "f3"
}
})
algo(leiden).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
phase1_loop_num: 5,
min_modularity_increase: 0.1,
edge_schema_property: 'weight'
}).write({
file: {
filename_community_id: "f1",
filename_ids: "f2",
filename_num: "f3"
}
})
Result:
_id,community_id
I,5
G,7
J,5
D,9
N,11
F,5
H,5
B,7
L,11
A,9
E,9
K,11
M,11
C,9
community_id,_ids
5,I;J;F;H;
7,G;B;
9,D;A;E;C;
11,N;L;K;M;
community_id,count
5,4
7,2
9,4
11,4
DB Writeback
Writes the community_id values from the results to the specified node property. The property type is uint32.
CALL algo.leiden.write("my_hdc_graph", {
return_id_uuid: "id",
phase1_loop_num: 5,
min_modularity_increase: 0.1,
edge_schema_property: 'weight'
}, {
db: {
property: "communityID"
}
})
algo(leiden).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
phase1_loop_num: 5,
min_modularity_increase: 0.1,
edge_schema_property: 'weight'
}).write({
db: {
property: 'communityID'
}
})
Stats Writeback
CALL algo.leiden.write("my_hdc_graph", {
return_id_uuid: "id",
phase1_loop_num: 5,
min_modularity_increase: 0.1,
edge_schema_property: 'weight'
}, {
stats: {}
})
algo(leiden).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
phase1_loop_num: 5,
min_modularity_increase: 0.1,
edge_schema_property: 'weight'
}).write({
stats: {}
})
Result:
| community_count | modularity |
|---|---|
| 4 | 0.548490 |
Full Return
CALL algo.leiden.run("my_hdc_graph", {
return_id_uuid: "id",
phase1_loop_num: 5,
min_modularity_increase: 0.1
}) YIELD r
RETURN r
exec {
algo(leiden).params({
return_id_uuid: "id",
phase1_loop_num: 5,
min_modularity_increase: 0.1
}) as r
return r
} on hdc_leiden
Result:
| _id | community_id |
|---|---|
| I | 5 |
| G | 7 |
| J | 5 |
| D | 9 |
| N | 11 |
| F | 5 |
| H | 5 |
| B | 7 |
| L | 11 |
| A | 9 |
| E | 9 |
| K | 11 |
| M | 11 |
| C | 9 |
Stream Return
This Stream Return supports two modes:
| Item | Spec | Columns |
|---|---|---|
mode |
1 (Default) |
|
2 |
|
CALL algo.leiden.stream("my_hdc_graph", {
return_id_uuid: "id",
phase1_loop_num: 6,
min_modularity_increase: 0.1
}) YIELD r
RETURN r
exec{
algo(leiden).params({
return_id_uuid: "id",
phase1_loop_num: 6,
min_modularity_increase: 0.1
}).stream() as r
return r
} on my_hdc_graph
Result:
| _id | community_id |
|---|---|
| I | 5 |
| G | 7 |
| J | 5 |
| D | 9 |
| N | 11 |
| F | 5 |
| H | 5 |
| B | 7 |
| L | 11 |
| A | 9 |
| E | 9 |
| K | 11 |
| M | 11 |
| C | 9 |
CALL algo.leiden.stream("my_hdc_graph", {
return_id_uuid: "id",
phase1_loop_num: 6,
min_modularity_increase: 0.1
}, {
mode: 2
}) YIELD r
RETURN r
exec{
algo(leiden).params({
return_id_uuid: "id",
phase1_loop_num: 6,
min_modularity_increase: 0.1,
order: "asc"
}).stream({
mode: 2
}) as r
return r
} on my_hdc_graph
Result:
| community_id | count |
|---|---|
| 7 | 2 |
| 5 | 4 |
| 9 | 4 |
| 11 | 4 |
Stats Return
CALL algo.leiden.stats("my_hdc_graph", {
return_id_uuid: "id",
phase1_loop_num: 6,
min_modularity_increase: 0.1
}) YIELD s
RETURN s
exec{
algo(leiden).params({
return_id_uuid: "id",
phase1_loop_num: 6,
min_modularity_increase: 0.1
}).stats() as s
return s
} on my_hdc_graph
Result:
| community_count | modularity |
|---|---|
| 4 | 0.397778 |