Why Ultipa
November 11, 2021
Graph database and graph computing construct the relationship between entities based on graph theory. Entities are expressed by vertices, while the relationship between entities is expressed by edges. This simple, free and high-dimensional way of data modeling that 100% restores the real world makes the calculation of the relationship between entities thousands of times more efficient than the SQL database.
The latest business scenarios and markets put forward rigid requirements for data association analysis and deep value extraction, which need to be met by technologies, products, and solutions based on graph computing, graph analysis, and graph storage. Over the past 20 years, tens of graph database service providers have emerged in the global IT market, from the traditional and academic RDF (resource definition framework) to the updated LPG (label & property graph), as well as various non-native graph solutions built on either the traditional SQL database or NoSQL databases, such as Oracle PGx Graph, or HBase + JanusGraph.
Most graph solutions may achieve 5-1000 times higher performance than traditional relational databases (such as Oracle or MySQL) when performing operations similar to join table, but they are helpless when facing scenarios of deep graph search, highly concurrent graph search, and real-time decision-making. For example, the graph systems developed by JanusGraph, Neo4j, ArangoDB, DGraph, Amazon Neptune, and BAT are almost nonplussed in the business environment, especially in the financial field, regardless of performance, function, or user experience.
Whether it is a database, data warehouse, data lake, data center, or computing engine, performance must be the absolute priority. A system with low performance won't exist long as a business support system, hence an authentic high-performance system (HPC/S both high-performance computing and storage) has the following three facts in common:
- HPC (High-Performance Computing): the highly parallel computing power
- HPS (High-Performance Storage): the comprehensive utilization and optimization of memory and external storage
- HPN (High-Performance Network): the high throughput and low latency system networking
Even the priority of these factors is defined, the computing power must be solved in the first place, then the storage, and finally the network ability. There is never a database system that can achieve high performance without fully releasing its computing power! Any graph computing system that advocates distributed storage while can not achieve concurrency on a single instance is a waste of resources and can not create real and sustainable business value.
Ultipa Graph is a revolutionary invention, its technologies have been tested in the most severe financial grade commercial scenarios with high concurrency and low latency requirements:
- High-Density Parallel Graph Computing
- Linear-Scalable Graph Computing
- Ultra-Deep Graph Traversal
- Dynamic Graph Pruning
Below are benefits brought by the application of these new technologies:
- Much Lower TCO (up to 70% cutdown)
- Faster Time-to-Value and Time-to-Market (80% reduction in the delivery cycle)
- Superb Usability (ease of use, availability, and stability of the whole system)
 Ultipa innovatively uses the high-density parallel graph computing infrastructure and concurrent memory data structure to build its graph database system and parallelizes all the operations, queries, calculations, and graph algorithms against graphs. Compared with the original serialized graph algorithm, Ultipa achieves an exponential performance improvement (vs. the graph algorithm supported by Python). This optimization is very different from the common web-centric distributed system built by Internet enterprises. The web is stateless while the graph calculation is stateful, and graph computing emphasizes integrity. The topology of each graph needs to be stored as a whole at the logical level, which is different from the distributed database (or distributed kV store) supporting the 'seckill' system regarding both design and implementation.
Ultipa innovatively uses the high-density parallel graph computing infrastructure and concurrent memory data structure to build its graph database system and parallelizes all the operations, queries, calculations, and graph algorithms against graphs. Compared with the original serialized graph algorithm, Ultipa achieves an exponential performance improvement (vs. the graph algorithm supported by Python). This optimization is very different from the common web-centric distributed system built by Internet enterprises. The web is stateless while the graph calculation is stateful, and graph computing emphasizes integrity. The topology of each graph needs to be stored as a whole at the logical level, which is different from the distributed database (or distributed kV store) supporting the 'seckill' system regarding both design and implementation.
Inefficient and wrong distributed system design will have the following characteristics:
- Extremely low overall performance of the system due to the exponential increase of data traffic among horizontally distributed instances, or even completely unavailable clusters;
- Super low concurrency scale projected to a single instance, which is a huge waste of underlying hardware resources caused by too low computing density.
Ultipa is committed to avoiding and solving the above two pain points with its below features:
- The Shared-Nothing architecture ensuring an always-available-cluster in the case of node (instance) offline;
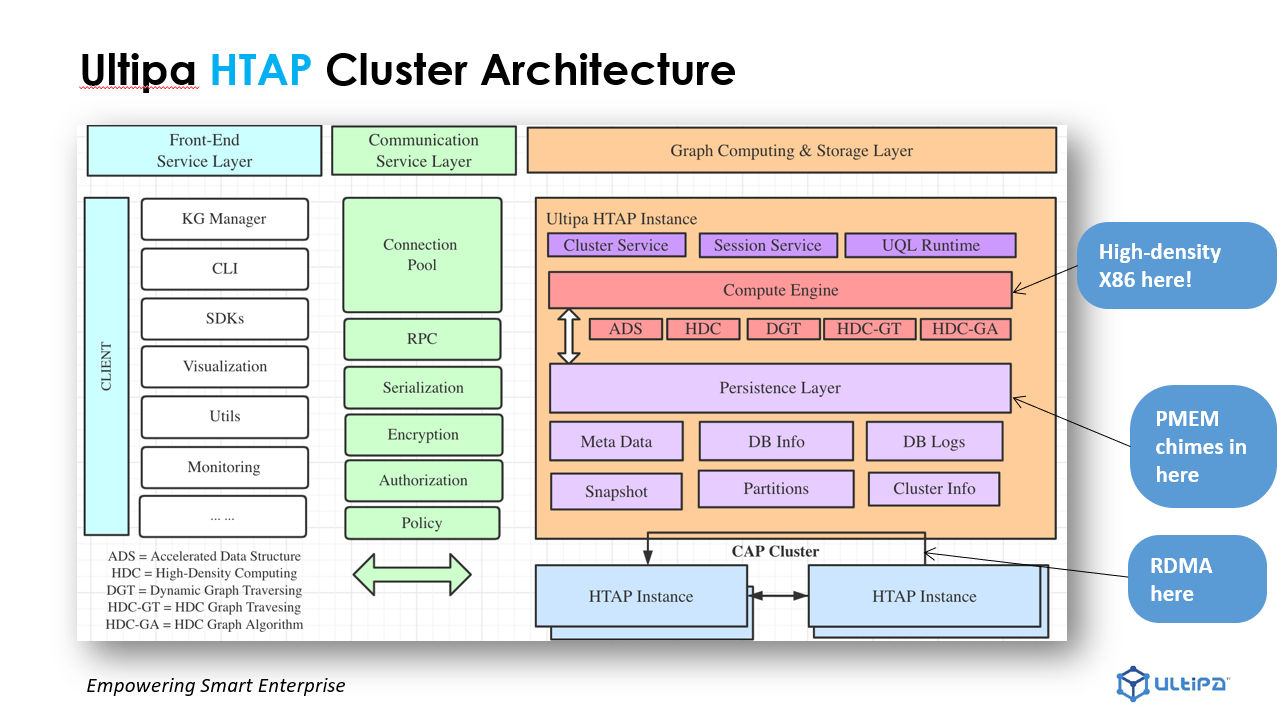
- The HTAP architecture integrating the data processing capabilities of OLTP + OLAP in a horizontally distributed cluster;
- Fully release the High-Density Parallel Computing power of underlying hardware, such as x86 CPU;
- The Linear Scalable system architecture designed for graph integrity;
- The ability of Deep Search implemented on the graph;
- The Dynamic Pruning capability that maintains or even augments the engine performance during graph computing, for example, depth graph traversal;
- CAP cluster ensuring cluster availability, partition, and data consistency (final consistency).
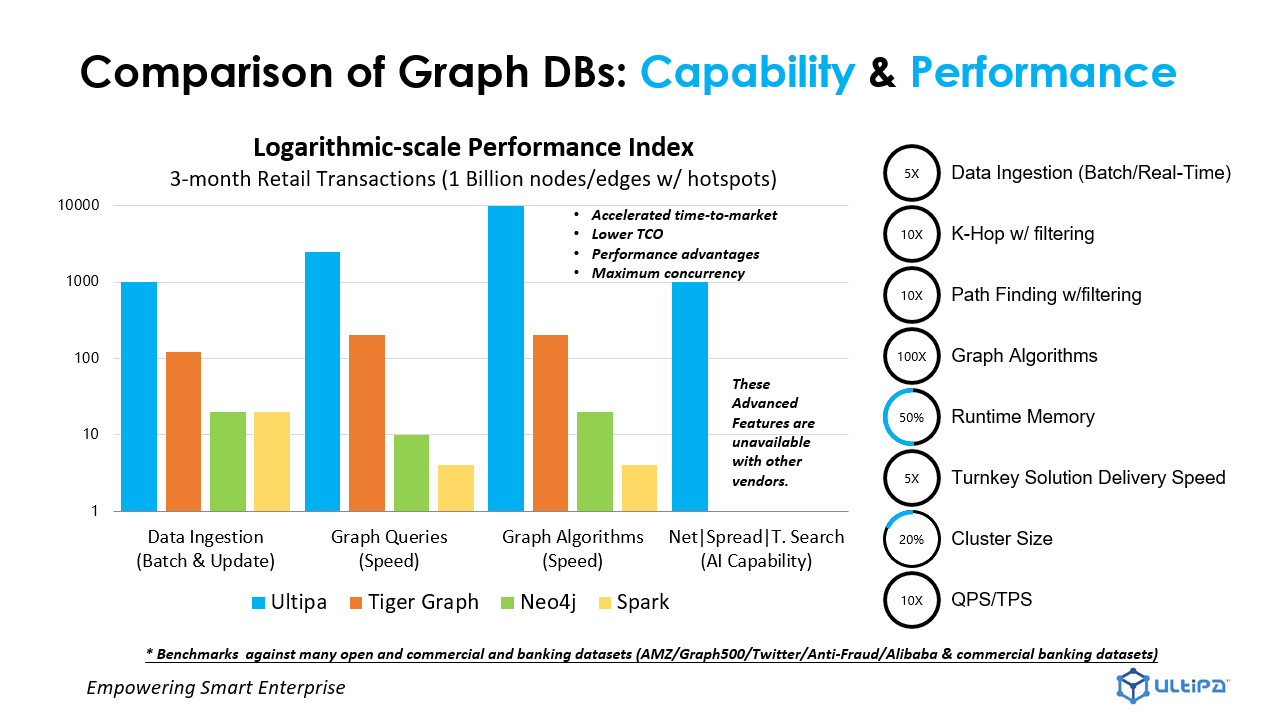
Ultipa Graph Database has been tested in real financial business scenarios for its comprehensive performance, function, stability, ease of use and integrability, in all dimensions such as batch data import, dynamic update, meta-data query, filtering, path query, khop query, and whole-graph algorithm. It has stable performance and is hundreds of times better than the mainstream products in the current market. Below is the comparison of evaluation results is between Ultipa and Neo4j, TigerGraph, Tencent, and BAT.