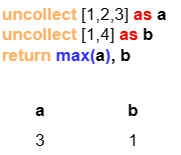Overview
In a UQL statement, multiple clauses are often involved, through which data retrieved from the database or constructed within the statement is sequentially passed and processed. Aliases are utilized to represent data, allowing clauses to call upon them for usage or further processing.
The data may contain multiple entries, which can be viewed for illustrative purposes as multiple rows, with each row containing one data entry. When a clause (especially a chained clause) calls aliases, the corresponding querying or computation is performed row by row.
Homologous Data
Data derived from one clause are referred to as homologous, and data produced by a clause remains homologous with the data that entered. Typically, all homologous data have the same number of rows, and the entries in the same row are correlated. This homogeneity extends to information extracted from homologous data.
Example: tail, path and length are homologous, they all have 5 rows.
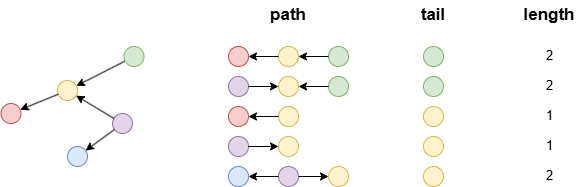
n().e()[:2].n(as tail).limit(5) as path
with length(path) as length
return path, tail, length
Example: n, n.score1, n.score2 and mean are homologous, they all have 4 rows.
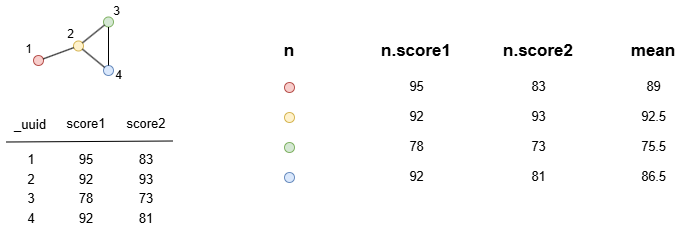
find().nodes() as n
return (n.score1 + n.score2) / 2 as mean
Aggregation
Aggregation functions condense data into a single row while discarding the other rows, and the homologous data of the aggregated data will also be affected. After aggregation, the remaining single rows of all homologous data streams are typically uncorrelated.
Example: n and n.score1 are homologous, originally with 4 rows; while n.score1 is aggregated in the RETURN clause and produces minS1, n is also reduced to only one row.

find().nodes() as n
return n, min(n.score1) as minS1
Deduplication
Applying deduplication to data usually reduces its number of rows, and the homologous data of the deduplicated data will also be affected. The left rows in all homologous data remain correlated by row.
The only exception occurs when deduplication takes place in the RETURN clause, where the homologous data of the deduplicated data will not be affected. Therefore, the row-wise correlation between the deduplicated data and its homologous data is lost.
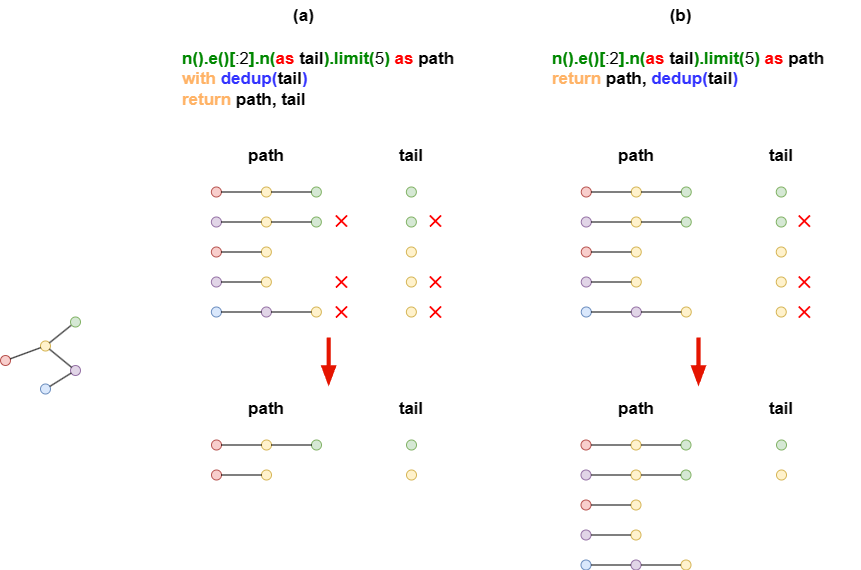
Example: tail and path are homologous, originally with 5 rows.
- In part (a) where
tailis deduplicated in theWITHclause, the corresponding rows inpathare discarded too. - In part (b) where
tailis deduplicated in theRETURNclause,pathis not affected.
Heterologous Data
Data derived from completely independent clauses are referred to as heterologous. Rows in heterologous data are usually uncorrelated and free to have a different number of rows.
When heterologous data enter into the same clause, they are typically automatically trimmed to the minimum length of all data to ensure they can be processed row by row. However. there are two exceptions to this rule:
- In the
WITHclause, a Cartesian product will be performed between all heterologous data. - In the
RETURNclause, heterologous data are not trimmed to the same length unless they are jointly used for some computation, or aggregation function is included.
Example: n1 and n2 are heterologous, each with a different number of rows; when they enter into the pathfinding clause together, the third row of n2 is discarded to ensure n1 and n2 have the same number of rows for processing.
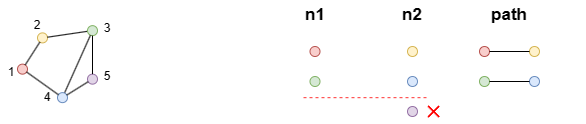
find().nodes({_uuid in [1, 3]}) as n1
find().nodes({_uuid in [2, 4, 5]}) as n2
n(n1).e().n(n2) as path
return path
WITH Clause
Example: a and c are homologous with 3 rows each, while b is heterologous with 2 rows; when c and b are used together in the WITH clause, a Cartesian product is performed between them. As a result, c and b become homologous and both contain 6 rows each.
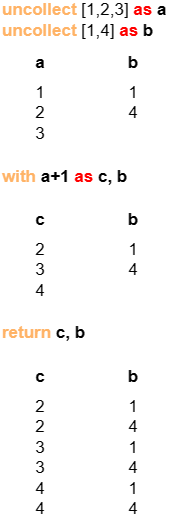
RETURN Clause
Example: a with 3 rows and b with 2 rows are heterologous.
- In part (a) where the computation on
bin theRETURNclause doesn't involvea,aandb+1return 3 rows and 2 rows respectively. - In part (b) where the computation of
cin theRETURNclause involve bothaandb,ais trimmed to 2 rows, andccontains 2 rows. However,aandbthat return independently are not affected.
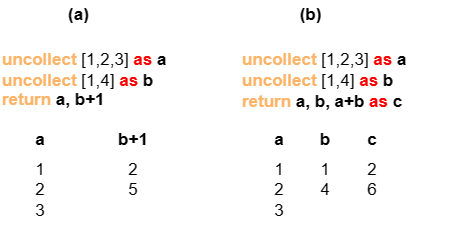
Example: a is aggregated in the RETURN clause, causing b to be left with 1 row as well.