
You can import data from various sources into Ultipa Graph in the Loader module. Supported data sources include CSV, JSON, JSONL, PostgreSQL, SQL Server, MySQL, BigQuery, Neo4j and Kafka.
Loader and Task
Within this module, you can create loaders, each containing multiple import tasks. Tasks within a loader can be executed individually or simultaneously (either serially or in parallel).
Create a Loader
Clicking the New Loader button on the Loader main page will create a loader with the default name My Loader.
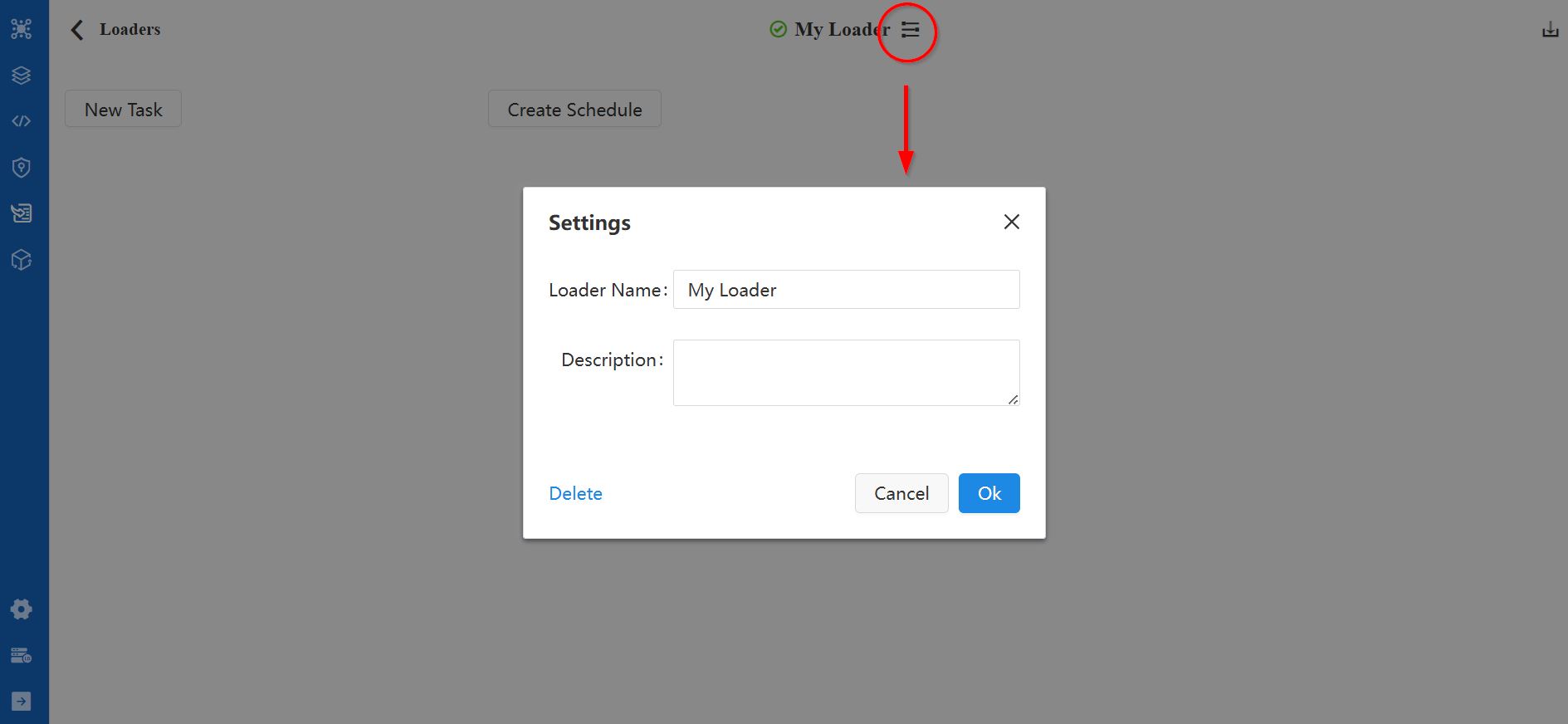
On the loader configuration page, you can rename the loader and modify its description by clicking the icon located next to the loader name.
Create a Task
To add a new task on the loader configuration page, click the New Task button and choose the type of data source for the task. You can add multiple tasks in a loader.

You can set the task name by double-clicking the corresponding area on the left side task card. On the right side is the task configurations. Please refer to the Appendix: Task Configurations for details.
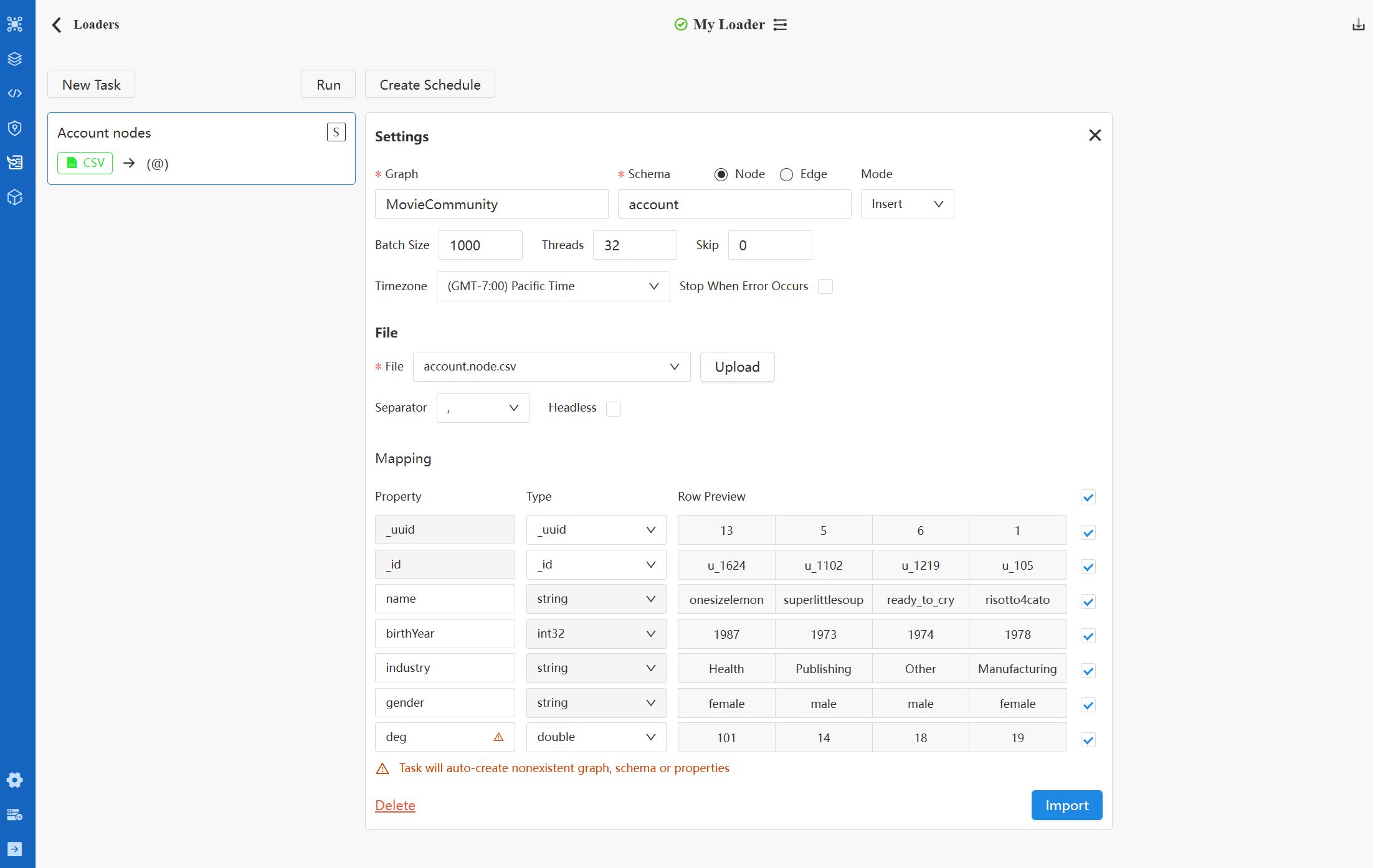
Import
Import Single Task
Click the Import button in certain task will execute the task immediately.
Run Loader
Click the Run button above the task list will trigger the import for all tasks within the loader, adhering to the designated order and processing mode:
- Tasks are executed from top to bottom. You can reorder tasks by dragging and dropping the task cards.
- Use the
S/Ptag on each task card to toggle between the Serial (one after the other; default) and Parallel (simultaneous) processing modes. - Adjacent
Ptasks along with theStask immediately preceding the topPtask form a parallel group, imported concurrently.
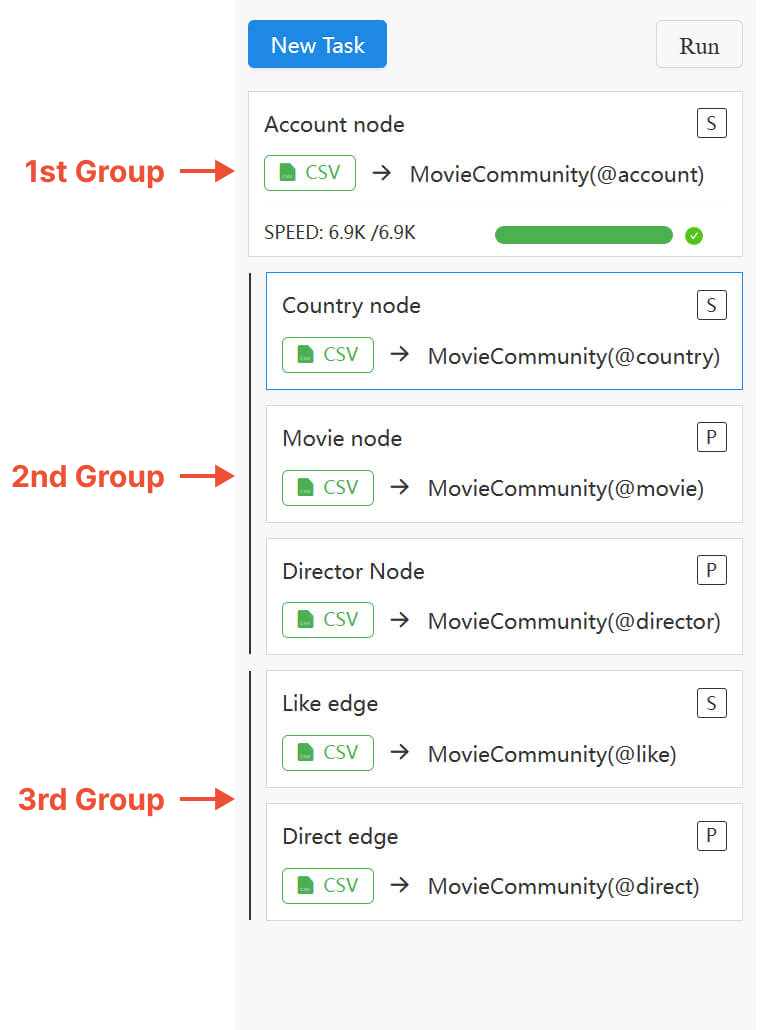
Errors may arise when importing nodes and edges concurrently, given that the creation of edges depends on the existence of their terminal nodes. Alternatively, consider importing nodes before edges, or ensure proper configuration of the Create Node If Not Exist option and the Insert/Upsert/Overwrite import mode.
Import Log
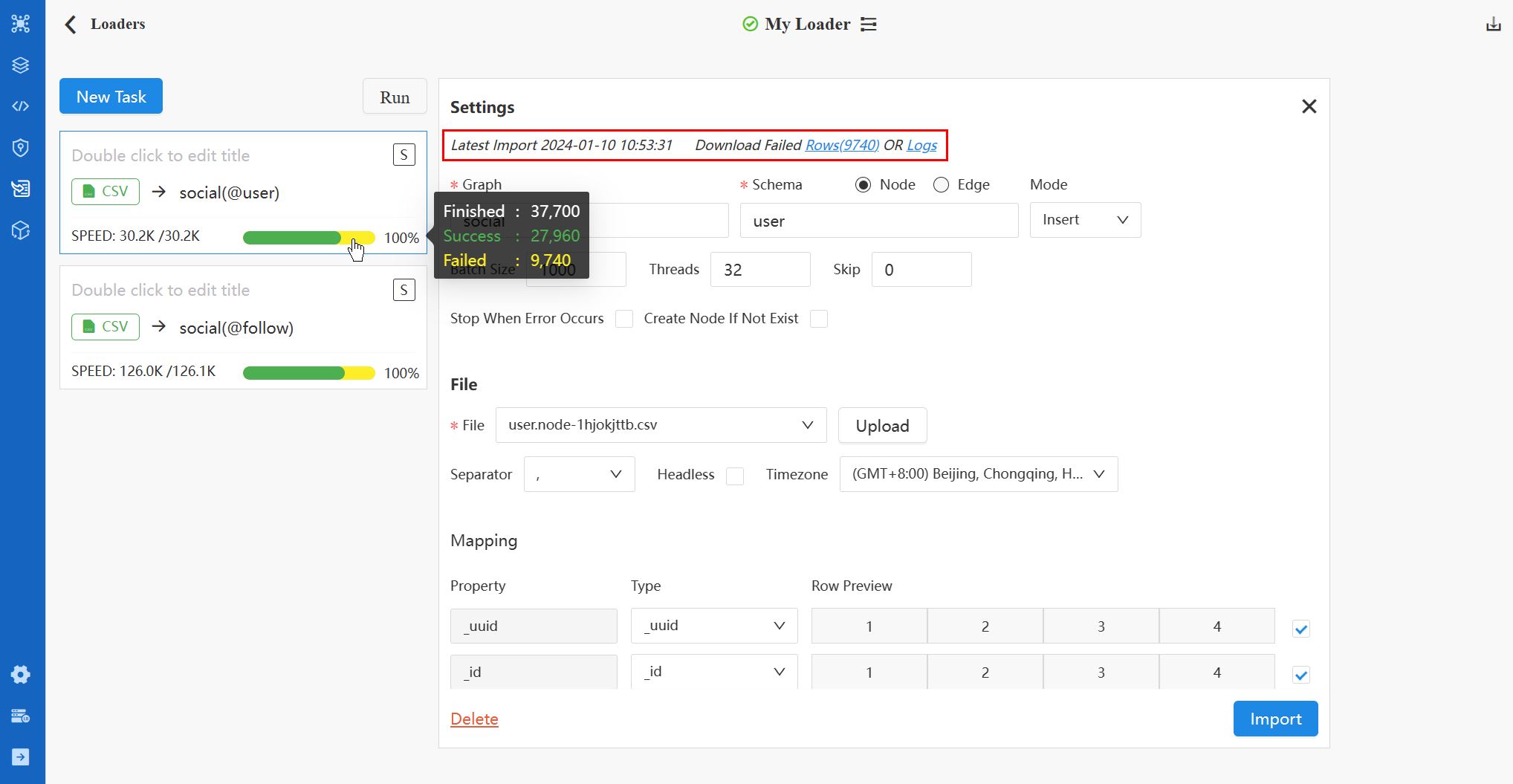
Typically, the SPEED indicator and process bar become visible on the task card once the import begins. A 100% successful import is denoted by a full green progress bar. However, if any errors occur during the task, a portion of the process bar turns yellow, reflecting the percentage of failed data rows.
At the top of the right-side configuration panel, the latest import log is displayed. Here, you can download the Failed Rows and Logs files.
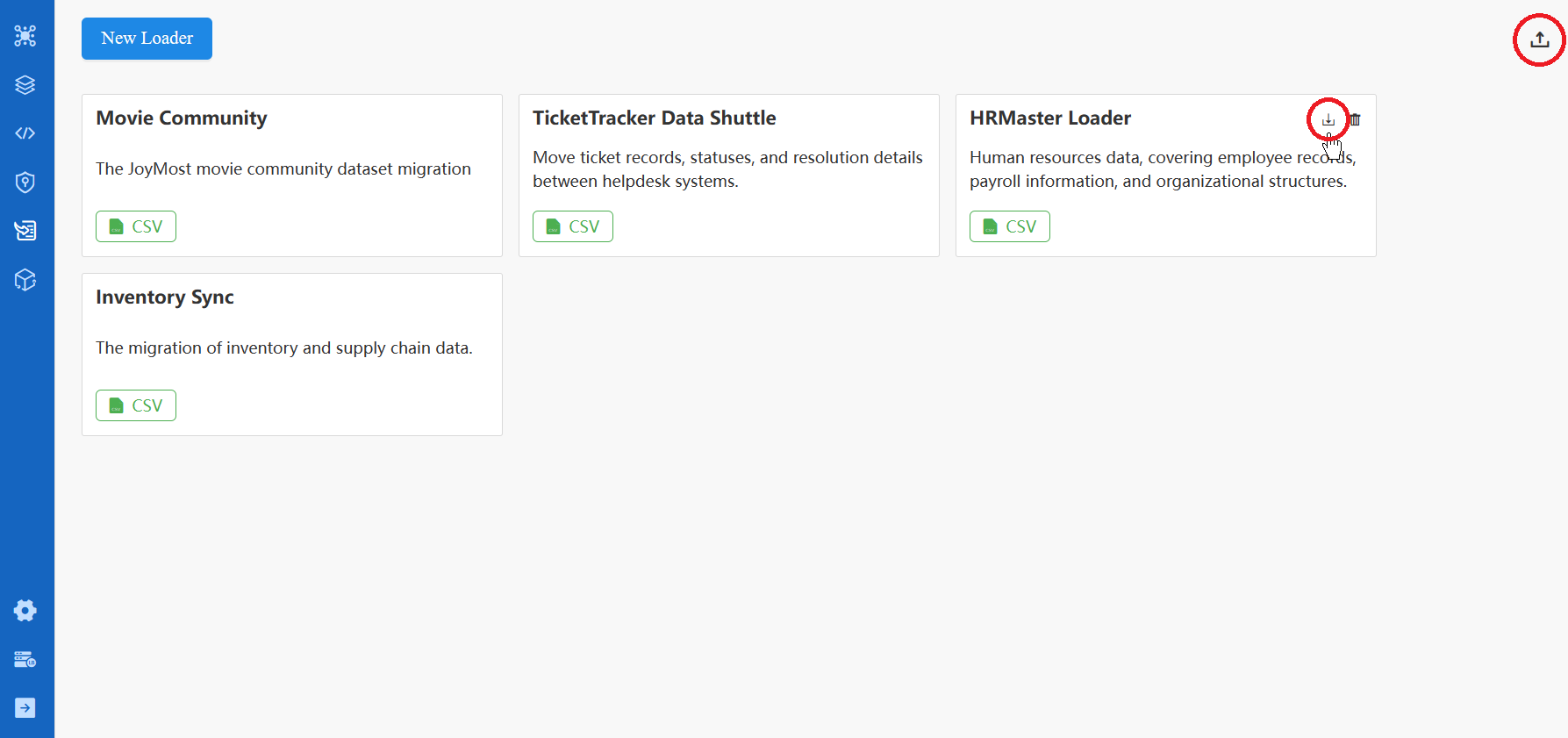
Import/Export Loader
You can export any loader as a ZIP file from the loader card. The option to import a loader is available at the top right of the Loader main page.
Appendix: Task Configurations
Settings
Task configurations vary for different data sources. However, the Settings part is common to all.
Item |
Description |
|---|---|
| Graph | Choose an existing graph or enter the name for a new graph. |
| Schema | Choose between Node and Edge. The Schema name field below populates with the corresponding schemas for the chosen existing graph. If creating a new graph, manually enter the schema name. |
| Mode | Select Insert, Upsert, or Overwrite as the import mode for the task. |
| Batch Size | Set the number of data rows included in each batch. |
| Threads | Set the maximum number of threads for the import process. |
| Skip | Set the number of initial data rows to be ignored during the import process. |
| Timezone | Select the timezone to convert timestamps to date and time; default is the timezone of your browser. |
| Stop When Error Occurs | Decide whether to halt the import process in case of an error. |
| Create Node If Not Exist | Decide Whether to create nonexistent terminal nodes when importing edges. If unchecked, edges without existing terminal nodes will not be imported and result in import errors. This option is only available for edge import task. |
Any new graph, schema, or property is flagged with a warning mark, indicating that they will be created during the import process.
CSV
File
Item |
Description |
|---|---|
| File | Upload a new CSV file from the local machine or choose a file previously uploaded. You can delete uploaded files from the dropdown list. |
| Separator | Specify the separator of the CSV file: choose between ,, ;, and |. |
| Headless | Indicate whether the CSV file starts with the header row (providing property names and types) or if it's headless with data rows only. |
Here is an example CSV file for @account nodes, including a header with property names and types:
_id:_id,username:string,brithYear:int32
U001,risotto4cato,1978
U002,jibber-jabber,1989
U003,LondonEYE,1982
Here is an example headless CSV file for @follow edges:
103,risotto4cato,jibber-jabber,1634962465
102,LondonEYE,jibber-jabber,1634962587
Mapping
After uploading or selecting the file, the Mapping section becomes visible:
Item |
Description |
|---|---|
| Property | Edit the property name. Fields are auto-populated if the CSV file has a header providing property names. |
| Type | Choose the property type. Fields are auto-populated with the property types specified in the header of the CSV file, or those detected based on the data. If the property name already exists under the specified schema, the type cannot be changed. |
| Row Preview | Preview of the first 4 data rows. |
| Include/Ignore | Uncheck the box to ignore the property during the import process. |
JSON, JSONL
File
Item |
Description |
|---|---|
| File | Upload a new JSON/JSONL file from the local machine or choose a file previously uploaded. You can delete uploaded files from the dropdown list. |
Here is an example JSON file for @user nodes:
[{
"_uuid": 1,
"_id": "U001",
"level": 2,
"registeredOn": "2018-12-1 10:20:23",
"tag": null
}, {
"_uuid": 2,
"_id": "U002",
"level": 3,
"registeredOn": "2018-12-1 12:45:12",
"tag": "cloud"
}]
Here is an example JSONL file for @user nodes:
{"_uuid": 1, "_id": "U001", "level": 2, "registeredOn": "2018-12-1 10:20:23", "tag": null}
{"_uuid": 2, "_id": "U002", "level": 3, "registeredOn": "2018-12-1 12:45:12", "tag": "cloud"
}
Mapping
After uploading or selecting the file, the Mapping section becomes visible:
Item |
Description |
|---|---|
| Property | Edit the property name. Fields are auto-populated with the keys in the file. |
| Type | Choose the property type. If the property name already exists under the specified schema, the type cannot be changed. |
| Original | Fields are auto-populated with the keys in the file. |
| Row Preview | Preview of the first 3 data rows. |
| Include/Ignore | Uncheck the box to ignore the property during the import process. |
PostgreSQL, SQL Server, MySQL
Source Database
Item |
Description |
|---|---|
| Host | The IP address of the database server. |
| Port | The port of the database server. |
| Database | Name of the database to import. |
| User | Username of the database server. |
| Password | Password of the user. |
| Test | Check if the connection can be successfully established. |
SQL
Write the SQL query to retrieve data from the database, then click Preview to map the results to the properties of the nodes or edges.
Here is an example SQL to return the name and registeredOn columns from the users table:
SELECT name, registeredOn FROM users;
Mapping
Once the SQL returns results, the Mapping section becomes visible:
Item |
Description |
|---|---|
| Property | Edit the property name. Fields are auto-populated with the column names in the query results. |
| Type | Choose the property type. Fields are auto-populated with the data type of each column in the query results. If the property name already exists under the specified schema, the type cannot be changed. |
| Original | Fields are auto-populated with the column names in the query results. |
| Row Preview | Preview the first 3 data rows. |
| Include/Ignore | Uncheck the box to ignore the property during the import process. |
BigQuery
Source Database
Item |
Description |
|---|---|
| Project ID | The ID for your Google Cloud Platform project. |
| Key (JSON) | The service account key, which is a JSON file. Upload a new JSON file from the local machine or choose a file previously uploaded. You can delete uploaded files from the dropdown list. |
| Test | Check if the connection can be successfully established. |
SQL
Write the SQL query to retrieve data from BigQuery, then click Preview to map the results to the properties of the nodes or edges.
Here is an example SQL to return all columns from the users table:
SELECT * FROM users;
Mapping
Once the SQL returns results, the Mapping section becomes visible:
Item |
Description |
|---|---|
| Property | Edit the property name. Fields are auto-populated with the column names in the query results. |
| Type | Choose the property type. Fields are auto-populated with the data type of each column in the query results. If the property name already exists under the specified schema, the type cannot be changed. |
| Original | Fields are auto-populated with the column names in the query results. |
| Row Preview | Preview the first 3 data rows. |
| Include/Ignore | Uncheck the box to ignore the property during the import process. |
Neo4j
Neo4j
Item |
Description |
|---|---|
| Host | The IP address of the database server. |
| Port | The port of the database server. |
| Database | Name of the database to import. |
| User | Username of the database server. |
| Password | Password of the user. |
| Test | Check if the connection can be successfully established. |
Cypher
Write the Cypher query to retrieve nodes or edges from Neo4j, then click Preview to map the results to the properties of the nodes or edges.
Here is an example Cypher to return all nodes with the user label:
MATCH (n:user)
Mapping
Once the Cypher returns results, the Mapping section becomes visible:
Item |
Description |
|---|---|
| Property | Edit the property name. Fields are auto-populated with the property names in the query results. |
| Type | Choose the property type. Fields are auto-populated with the property types in the query results. If the property name already exists under the specified schema, the type cannot be changed. |
| Original | Fields are auto-populated with the property names in the query results. |
| Row Preview | Preview of the first 3 data rows. |
| Include/Ignore | Uncheck the box to ignore the property during the import process. |
Kafka
Kafka
Item |
Description |
|---|---|
| Host | The IP address of the server where the Kafka broker is running. |
| Port | The port on which the Kafka broker listens for incoming connections. |
| Topic | The topic where messages (data) are published. |
| Offset | Select the offset to specify which messages you want to consume (import): - Newest: Receive messages published after the consumer (task) starts.- Oldest: Receive all messages currently stored in the topic and messages published after the consumer starts.- Since: Receive messages published after the set date and messages published after the consumer starts.- Index: Receive messages whose indexes equal to or are greater than the set index, and messages published after the consumer starts. |
| Test | Check if the connection can be successfully established. |
| Preview | Map the retrieved messages to the properties of the nodes or edges. |
Mapping
Once there are messages returned after clicking Preview, the Mapping section becomes visible:
Item |
Description |
|---|---|
| Property | Edit the property name. Property values are identified within the message content by commas (,), and the default property names are col<N>. |
| Type | Choose the property type. If the property name already exists under the specified schema, the type cannot be changed. |
| Row Preview | Preview the first 4 data rows. |
| Include/Ignore | Uncheck the box to ignore the property during the import process. |
The Kafka task (consumer), once started, will continue running to import newly published messages. You need to manually stop the task as needed.