
Vue d’ensemble
L'instruction CALL vous permet d'exécuter une procédure, soit seule, soit comme partie intégrante d'une requête plus large. Une procédure peut être soit définie par le système (appelée procédure nommée), soit définie manuellement dans la requête (appelée procédure en ligne).
<call procedure statement> ::= [ "OPTIONAL" ] "CALL" <procedure call>
<procedure call> ::= <named procedure call> | <inline procedure call>
Détails
- Le mot-clé
OPTIONALpeut être utilisé pour gérer les cas où la procédure pourrait ne pas retourner de résultats. Si aucun résultat n'est trouvé, il produit des valeursnullà la place.
Exemple de Graph
Les exemples suivants s'exécutent sur ce graph :
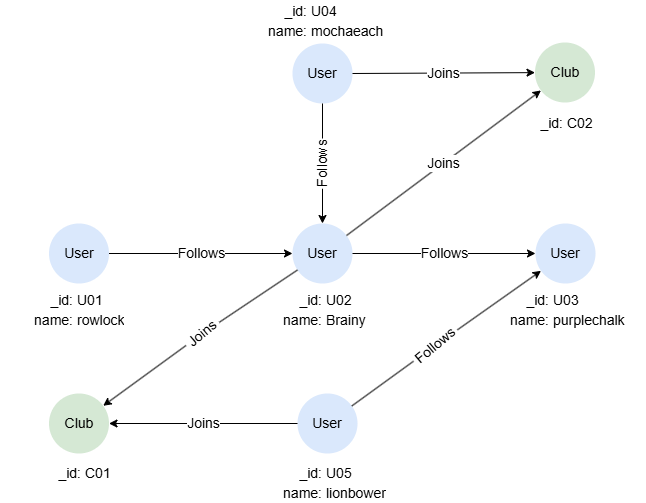
Pour créer ce graph, exécutez la requête suivante sur un graph vide :
INSERT (rowlock:User {_id:'U01', name:'rowlock'}),
(brainy:User {_id:'U02', name:'Brainy'}),
(purplechalk:User {_id:'U03', name:'purplechalk'}),
(mochaeach:User {_id:'U04', name:'mochaeach'}),
(lionbower:User {_id:'U05', name:'lionbower'}),
(c01:Club {_id:'C01'}),
(c02:Club {_id:'C02'}),
(rowlock)-[:Follows]->(brainy),
(mochaeach)-[:Follows]->(brainy),
(brainy)-[:Follows]->(purplechalk),
(purplechalk)-[:Follows]->(brainy),
(lionbower)-[:Follows]->(purplechalk),
(brainy)-[:Joins]->(c01),
(lionbower)-[:Joins]->(c01),
(mochaeach)-[:Joins]->(c02)
Appels de Procédure Nommée
L'instruction CALL peut invoquer une procédure prédéfinie déployée dans la base de données. Ultipa offre une gamme de procédures intégrées.
<named procedure call> ::=
<procedure reference> "(" [ <procedure argument list> ] ")" [ <yield clause> ]
<procedure argument list> ::=
<procedure argument> [ { "," <procedure argument> }... ]
<procedure argument> ::= <value expression>
Détails
- La clause
YIELDpeut être utilisée pour sélectionner et renommer les colonnes de la table de liaison (si disponible) produite par la procédure nommée, permettant de les exposer et de les référencer dans les parties suivantes de la requête.
Création d’un Graph HDC
Cette requête appelle la procédure hdc.graph.create pour projeter tout le graph actuel en tant que graph HDC hdc_g1 sur le serveur HDC hdc-server-1 :
CALL hdc.graph.create("hdc-server-1", "hdc_g1", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
query: "query",
type: "Graph",
update: "static",
default: true
})
Affichage du Graph HDC
Cette requête appelle la procédure hdc.graph.show pour récupérer tous les graphs HDC du graph actuel :
CALL hdc.graph.show()
Résultat : _projectList
| project_name | project_type | filter_type | is_default | graph_name | status | stats | hdc_server_name | hdc_server_status | config |
|---|---|---|---|---|---|---|---|---|---|
| hdc_g1 | central | hdc_graph | true | Doc7 | DONE | {"edge_count":7,"edge_schema":{"Follows":{"id":2,"name":"Follows","properties":null},"Joins":{"id":3,"name":"Joins","properties":null}},"node_count":7,"node_schema":{"Club":{"id":3,"name":"Club","properties":null},"User":{"id":2,"name":"User","properties":[{"id":101,"name":"name","sub_types":null,"type":7}]}}} | hdc-server-1 | ALIVE | {"edge_schema_map":"{"Follows":[],"Joins":[],"default":[]}","hdc_server_name":"hdc-server-1","job_type":"central","node_schema_map":"{"Club":[],"User":["name"],"default":[]}","orientation":"Graph","query":"query","shard_ids":[1],"update":"static"} |
Cette requête appelle la procédure hdc.graph.show pour récupérer le graph HDC hdc_g1 du graph actuel :
CALL hdc.graph.show("hdc_g1")
Suppression du Graph HDC
Cette requête appelle la procédure hdc.graph.drop pour supprimer le graph HDC hdc_g2 du graph actuel :
CALL hdc.graph.drop("hdc_g2")
Affichage des Tâches
Cette requête appelle la procédure job.show pour récupérer toutes les tâches dans le graph actuel :
CALL job.show()
Résultat: result
| job_id | graph_name | type | uql | status | err_msg | result | start_time | end_time | progress |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Doc7 | CREATE_HDC_GRAPH | CALL hdc.graph.create("hdc-server-1", "hdc_g1", { nodes: {"": [""]}, edges: {"": [""]}, query: "query", type: "Graph", update: "static", default: true }) | FINISHED | {"edge_count":7,"edge_schema":{"Follows":{"id":2,"name":"Follows","properties":null},"Joins":{"id":3,"name":"Joins","properties":null}},"node_count":7,"node_schema":{"Club":{"id":3,"name":"Club","properties":null},"User":{"id":2,"name":"User","properties":[{"id":101,"name":"name","sub_types":null,"type":7}]}}} | 2024-09-18 17:54:55 | 2024-09-18 17:54:57 |
Cette requête appelle la procédure job.show pour récupérer la tâche avec job_id comme 1 dans le graph actuel :
CALL job.show("1")
Exécution de l'Algorithme HDC
Cette requête appelle la procédure hdc.algo.degree pour exécuter l'algorithme de Centralité de Degré sur le graph HDC hdc_g1 :
call hdc.algo.degree("hdc_g1", {
order: "desc"
}) YIELD r
RETURN r
Résultat: r
| _uuid | degree_centrality |
|---|---|
| 13042426719888211970 | 5.000000 |
| 3602881900919652355 | 3.000000 |
| 1585269267857670149 | 2.000000 |
| 3458766712843796484 | 2.000000 |
| 1008809615065874438 | 2.000000 |
| 18374688678694879233 | 1.000000 |
| 576464050838306823 | 1.000000 |
Exécution de l'Algorithme HDC avec Rétroécriture
Cette requête appelle la procédure hdc.algo.degree.write pour exécuter l'algorithme de Centralité de Degré sur le graph HDC hdc_g1 et écrire les résultats dans le fichier degree.txt :
CALL hdc.algo.degree.write("hdc_g1", {
params: {
order: "desc"
},
return_params: {
file: {
filename: "degree.txt"
}
}
})
Appels de Procédure En Ligne
<inline procedure call> ::= [ <variable scope clause> ] <nested procedure specification>
<variable scope clause> ::= "(" [ <binding variable reference list> ] ")"
<binding variable reference list> ::=
<binding variable reference> [ { "," <binding variable reference> }... ]
<binding variable reference> ::= <binding variable>
<nested procedure specification> ::= "{" <procedure specification> "}"
<procedure specification> ::=
<catalog-modifying procedure specification>
| <data-modifying procedure specification>
| <query specification>
<catalog-modifying procedure specification> ::= <procedure body>
<nested data-modifying procedure specification> ::=
"{" <data-modifying procedure specification> "}"
<data-modifying procedure specification> ::= <procedure body>
<nested query specification> ::= "{" <query specification> "}"
<query specification> ::= <procedure body>
<procedure body> ::= <statement block>
<statement block> ::= <statement> [ <next statement>... ]
<statement> ::=
<linear catalog-modifying statement>
| <linear data-modifying statement>
| <composite query statement>
<next statement> ::=
"NEXT" [ <yield clause> ] <statement>
L'appel de procédure en ligne peut être construit avec ou sans importation de variables des parties antérieures de la requête en utilisant la clause de portée de variables.
Lorsqu'il y a des variables importées, la procédure en ligne est effectivement une sous-requête, qui s'exécute plusieurs fois, chaque fois opérant sur un seul enregistrement des variables importées.
Une sous-requête se termine généralement par une clause RETURN. Chaque ligne produite par une exécution est ajoutée sur le côté droit de la ligne d'entrée correspondante. Lorsqu'une exécution ne produit pas de lignes de sortie, la ligne d'entrée associée est supprimée. Inversement, si une exécution produit plusieurs lignes de sortie, la ligne d'entrée correspondante est dupliquée pour chaque ligne de sortie, permettant aux résultats d'être concaténés en conséquence.
Les sous-requêtes sans RETURN sont utilisées pour des opérations de modification de données telles que INSERT, SET, REMOVE et DELETE. Comme ces sous-requêtes ne retournent explicitement aucun résultat, le nombre de lignes présentes après la sous-requête reste le même qu'avant la sous-requête.
Lorsqu'il n'y a pas de variables importées, la procédure en ligne ne s'exécute qu'une seule fois.
Requête Isolée
Dans cette requête, la sous-requête CALL est utilisée pour trouver le club rejoint par chaque utilisateur :
MATCH (u:User)
CALL (u) {
MATCH (u)-[:Joins]-(c:Club)
RETURN c
}
RETURN u.name, c.code
Résultat :
| u.name | c.code |
|---|---|
| mochaeach | C02 |
| Brainy | C01 |
| lionbower | C01 |
Les sous-requêtes
CALLaméliorent l'efficacité en gérant mieux les ressources, particulièrement lors du traitement de grands ensembles de données, réduisant ainsi la surcharge mémoire.
Agrégation Isolée
Dans cette requête, la sous-requête CALL est utilisée pour compter le nombre total d'abonnés pour chaque utilisateur qui rejoint un club :
MATCH (u:User)-[:Joins]-(c:Club)
CALL (u) {
MATCH (u)<-[:Follows]-(follower)
RETURN COUNT(follower) AS followersNo
}
RETURN u.name, c.code, followersNo
Résultat :
| u.name | c.code | followersNo |
|---|---|---|
| Brainy | C01 | 3 |
| lionbower | C01 | 0 |
| mochaeach | C02 | 0 |
Modification de Données Isolée
Dans cette requête, la sous-requête CALL est utilisée pour définir les valeurs de la property rates des edges étiquetées Joins:
MATCH (u:User)-[j:Joins]-(c:Club)
CALL (j) {
SET j.rates = ROUND(RAND()*10, 2)
}
RETURN u.name, j.rates, c.code
Résultat :
| u.name | j.rates | c.code |
|---|---|---|
| Brainy | 9.67 | C01 |
| lionbower | 6.14 | C01 |
| mochaeach | 6.45 | C02 |
Importation de Variables Multiples
Dans cette requête, la sous-requête CALL est utilisée pour détecter la relation de suivi inversée entre deux utilisateurs, où il est connu que l'un suit l'autre :
MATCH (u1:User)<-[:Follows]-(u2:User)
CALL (u1, u2) {
OPTIONAL MATCH p = (u1)-[:Follows]->(u2)
RETURN p
}
RETURN u1.name, u2.name,
CASE p WHEN IS NOT NULL THEN "Y"
ELSE "N" END AS MutualFollowing
Résultat :
| u1.name | u2.name | MutualFollowing |
|---|---|---|
| Brainy | rowlock | N |
| Brainy | mochaeach | N |
| purplechalk | Brainy | Y |
| purplechalk | lionbower | N |
Aucune Variable Importée
Dans cette requête, la sous-requête CALL est utilisée sans importer de variables et elle est exécutée deux fois :
MATCH (c:Club)
CALL {
MATCH (u:User)
RETURN COUNT(u) AS totalUsers
}
RETURN COUNT(c) AS totalClubs, totalUsers
Résultat :
| totalClubs | totalUsers |
|---|---|
| 2 | 5 |
Sous-Requêtes CALL Multiples
Dans cette requête, la première sous-requête CALL est utilisée pour définir les valeurs de la property rates des edges étiquetées Joins, la deuxième sous-requête CALL est utilisée pour compter la note moyenne que chaque club reçoit :
MATCH (u:User)-[j1:Joins]-(c:Club)
CALL (j1) {
SET j1.rates = ROUND(RAND()*10, 2)
}
CALL (c) {
MATCH (c)-[j2]-()
RETURN ROUND(AVG(j2.rates), 2) as rating
}
RETURN u.name, j1.rates, c.code, rating
Résultat :
| u.name | j1.rates | c.code | rating |
|---|---|---|---|
| Brainy | 8.58 | C01 | 7.37 |
| lionbower | 6.15 | C01 | 7.37 |
| mochaeach | 8.5 | C02 | 8.5 |
Ordre d’Exécution des Sous-Requêtes
L'ordre dans lequel la sous-requête est exécutée n'est pas prédéterminé. Si un ordre d'exécution spécifique est souhaité, la clause ORDER BY doit être utilisée avant la sous-requête CALL pour imposer cette séquence.
Dans cette requête, la sous-requête CALL est utilisée pour compter le nombre total d'abonnés pour chaque utilisateur ; l'ordre d'exécution des sous-requêtes est déterminé par l'ordre croissant des noms des utilisateurs :
MATCH (u:User)
ORDER BY u.name
CALL (u) {
MATCH (u)<-[:Follows]-(follower)
RETURN COUNT(follower) AS followersNo
}
RETURN u.name, followersNo
Résultat :
| u.name | followersNo |
|---|---|
| Brainy | 3 |
| lionbower | 0 |
| mochaeach | 0 |
| purplechalk | 2 |
| rowlock | 0 |