
Cette page explique à quoi ressemblent les données graphe et comment elles sont décrites en UQL. Cela doit être maîtrisé avant d'apprendre et d'utiliser le Système Ultipa Graph.
Données Graph
Node
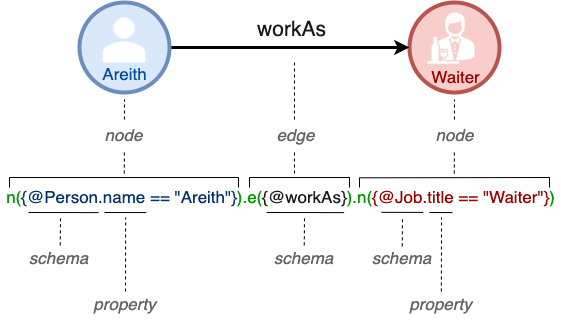
Les deux cercles Areith et Serveur montrés dans le Graphique1 sont des nodes.
Les nodes représentent des entités dans le monde.
Edge
La flèche noire travaillerComme dans le Graphique1 est une edge, elle pointe de Areith vers Serveur.
Les edges représentent des relations entre les entités.
Schema
Les Personne, Emploi et travaillerComme dans le code du Graphique1 sont des schemas.
Les schemas représentent différents types de node ou edge.
Property
Les nom et titre dans le code du Graphique1 sont des properties.
Les properties sont les composants d'un schema pour décrire en détail le type de node ou edge que ce schema représente.
Path
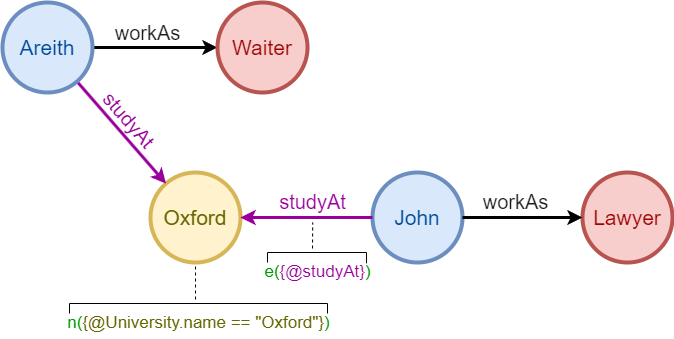
La séquence de nodes et edges connectés et alternés Areith, travaillerComme et Serveur dans le Graphique2 est un path. Une autre séquence Serveur, travaillerComme, Areith, étudierÀ, Oxford est aussi un path.
Un path commence et se termine par un node, contient au moins une edge. Il représente des corrélations multi-étapes des entités, ce qui le rend le plus interrogé dans le calcul graphe.
Décrire les Nodes
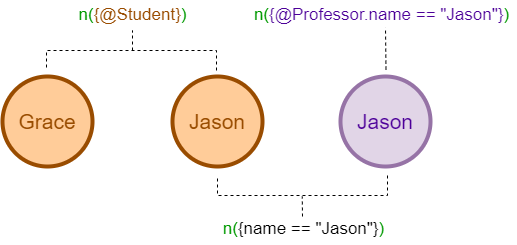
Il y a un ensemble de paramètres qui peuvent décrire des node(s) en UQL. Prenons le paramètre n() comme exemple :
n() // n'importe quel node dans le graphe
n({@Élève}) // nodes du schema 'Élève'
n({name == "Jason"}) // nodes dont la property 'name' est 'Jason'
n({@Élève.name == "Jason"}) // nodes du schema 'Élève' dont la property 'name' est 'Jason'
n(as a) // n'importe quel node dans le graphe, et donner à ces nodes un alias 'a'
n({@Élève} as a) // ...
...
Caractéristiques pour décrire les nodes en utilisant n() :
- Un
n()sans{}ou avec des accolades vides{}ne fixe aucune exigence particulière sur les nodes - Le filtrage de schema nécessite le symbole
@ - Schema et property peuvent être filtrés en combinaison ou séparément
- Assigner un alias aux nodes trouvés nécessite le mot-clé
assuivant{}(si présent)
Tous les paramètres qui peuvent décrire des node(s) en UQL :
nodes(): utilisé dans la requête, mise à jour et suppression de nodesn(): utilisé dans la requête de modèle pour désigner un node dans le pathnf(): utilisé dans la requête de modèle pour désigner des nodes consécutifs dans le pathsrc(): utilisé dans la requête de path non-template pour désigner le node initial du pathdest(): utilisé dans la requête de path non-template pour désigner le node terminal du pathnode_filter(): utilisé dans la requête de path non-template pour désigner tous les nodes autres quesrc()etdest()
Décrire les Edges
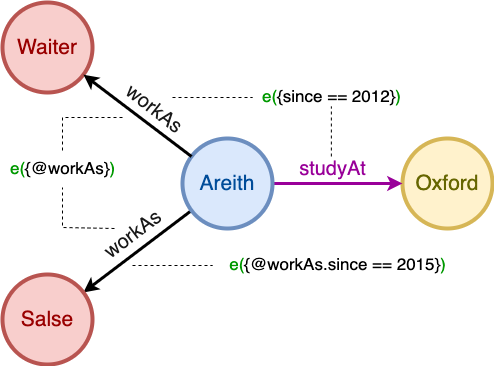
Prenons e() comme exemple pour voir comment les edges peuvent être décrites :
e() // n'importe quelle edge dans le graphe
e({@travaillerComme}) // edges du schema 'travaillerComme'
e({depuis == 2012}) // edges dont la property 'depuis' est '2012'
e({@travaillerComme.depuis == 2012}) // edges du schema 'travaillerComme' dont la property 'depuis' est '2012'
e(as b) // n'importe quelle edge dans le graphe, et donner à ces edges un alias 'b'
e({@travaillerComme} as b) // ...
...
Similaire à la description des nodes utilisant n(), décrire les edges en utilisant e() a les caractéristiques ci-dessous :
- Un
e()sans{}ou avec des accolades vides{}ne fixe aucune exigence particulière sur les edges - Le filtrage de schema nécessite le symbole
@ - Schema et property peuvent être filtrés en combinaison ou séparément
- Assigner un alias aux edges trouvées nécessite le mot-clé
assuivant{}(si présent), et une()représentant des edges consécutives ne supporte pas la définition d'un alias
Tous les paramètres qui peuvent décrire des edge(s) en UQL :
edges(): utilisé dans la requête, mise à jour et suppression de edgese(): utilisé dans la requête de modèle pour désigner une ou des edges consécutives dans le pathle(): utilisé dans la requête de modèle, similaire àe()mais pointant vers la gauchere(): utilisé dans la requête de modèle, similaire àe()mais pointant vers la droiteedge_filter(): utilisé dans la requête de path non-template pour désigner toutes les edges dans le path
Décrire les Paths (Modèle)
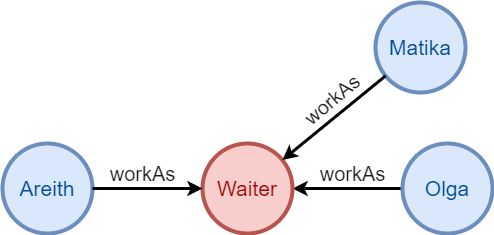
Les paths décrits à l'aide de n() et e() sont des modèles :
// n'importe quel path à 1 saut dans le graphe
n().e().n()
// n'importe quel path à 2 sauts dans le graphe
n().e().n().e().n()
n().e()[2].n()
// paths à 1 saut 'Person-travaillerComme-serveur'
// donner à ces Personne un alias 'individuel', donner à ces paths un alias 'carrière'
n({@Person} as individual).e({@travaillerComme}).n({@Emploi.titre == "Serveur"}) as carrière
// paths à 2 sauts 'Areith-travaillerComme-Emploi-travaillerComme-Personne'
// donner à ces Emploi un alias 'emploi', donner à ces Personne à la fin un alias 'autre'
n({@Person.name == "Areith"}).e({@travaillerComme}).n({@Emploi} as emploi).e({@travaillerComme}).n({@Person} as autre)
...
Caractéristiques du modèle de path :
- Les modèles de path sont aussi intuitifs qu'ils sont visualisés dans un graphe
- Un alias peut être assigné pour un single node, edge, ainsi que pour le path entier
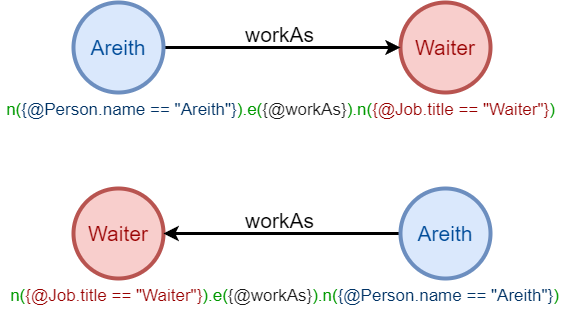
Les deux paths décrits dans le Graphique6 sont-ils les mêmes ? Comme les paths dans Ultipa sont composés et analysés de gauche à droite, les deux modèles ne sont pas les mêmes, mais ils décrivent les mêmes données graphe.