
Vue d’ensemble
GraphSAGE (SAmple and aggreGatE) est un cadre inductif polyvalent. Au lieu d'entraîner des intégrations distinctes pour chaque node, il apprend des fonctions qui génèrent des intégrations en échantillonnant et en agrégeant des caractéristiques du voisinage local d'un node. Cela permet de générer efficacement des intégrations de node pour de nouvelles données. GraphSAGE a été proposé par W.H Hamilton et al. de l'Université de Stanford en 2017:
- W.L. Hamilton, R. Ying, J. Leskovec, Inductive Representation Learning on Large Graphs (2017)
L'algorithme GraphSAGE est destiné à produire des intégrations de node en utilisant un modèle GraphSAGE entraîné. Le processus d'entraînement est décrit dans GraphSAGE Train.
Concepts
Cadre Transductif et Inductif
La plupart des méthodes conventionnelles d’intégration de graph apprennent des intégrations de node en utilisant des informations de tous les nodes tout au long des itérations. Lorsque de nouveaux nodes sont introduits dans le réseau, le modèle doit être réentraîné en utilisant l'ensemble du jeu de données. Ces cadres transductifs ne s'étendent pas naturellement pour se généraliser.
GraphSAGE, en revanche, agit comme un cadre inductif. Il entraîne une collection de fonctions d'agrégation plutôt que de créer des intégrations individuelles pour chaque node. Cela permet de dériver des intégrations pour les nodes nouvellement ajoutés en se basant sur les caractéristiques et les détails structurels des nodes existants, éliminant ainsi le besoin de reprendre toute la procédure d'entraînement. Cette capacité inductive est cruciale pour les systèmes d'apprentissage automatique opérationnels à haut débit.
GraphSAGE : Génération d’Intégration
Supposons que nous ayons déjà entraîné les paramètres de K fonctions d'agrégation (notées AGGREGATEk) et K matrices de poids (notées Wk). Décrivons maintenant le processus de génération des intégrations GraphSAGE (c'est-à-dire la propagation avant).
1. Échantillonnage de Voisinage
Dans le graph G = (V, E), pour chaque node cible à générer l'intégration, échantillonner quelques nodes de sa 1ère couche de voisinage à la K-ème couche de voisinage :
- Le nombre de nodes échantillonnés à chaque couche est fixé à Sk (k = 1,2,...,K).
- L'échantillonnage se fait de la couche 1 à la couche K, en obtenant les ensembles de nodes Bk (k = K,...,1,0).
- Initialiser BK avec tous les nodes cibles.
- Lors de l'échantillonnage à la couche k, obtenir l'ensemble BK-k en prenant l'union de BK-k+1 et de la collection de nodes échantillonnés à la couche k.
- L'échantillonnage est généralement effectué de manière uniforme. Si le nombre de voisins à une couche est inférieur au nombre défini, effectuer un échantillonnage répété jusqu'à ce que le nombre désiré de nodes soit atteint.
Les créateurs de GraphSAGE ont observé que la valeur de K ne doit pas être grande; un succès pratique peut être atteint même avec des valeurs modestes, telles que K = 2, étant donné que S1·S2 est inférieur à 500.
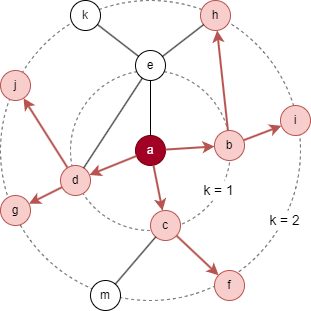
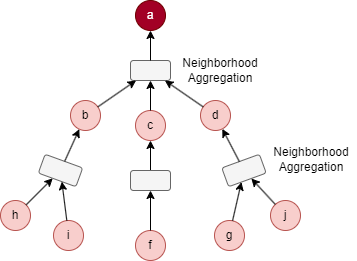
Pour le node cible a dans le graph ci-dessus, en considérant les paramètres K = 2, S1 = 3, et S2 = 5. B2 est initialisé comme {a}.
- L'échantillonnage commence à la 1ère couche : 3 voisins immédiats sont sélectionnés, donnant N(a) = {b, c, d}, puis B1 = B2 ⋃ N(a) = {a, b, c, d}.
- Ensuite, l'échantillonnage est effectué à la 2ème couche : 5 voisins sont sélectionnés sur la base des nodes dans N(a), donnant N(b) = {i, h}, N(c) = {f}, N(d) = {g, j}, ce qui donne B0 = B1 ⋃ N(b) ⋃ N(c) ⋃ N(d) = {a, b, c, d, f, g, h, i, j}.
2. Agrégation de Caractéristiques
Pour chaque node v ∈ B0, initialiser leurs vecteurs d'intégration comme leurs vecteurs de caractéristiques :
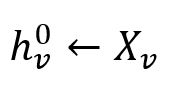
où chaque vecteur de caractéristiques Xv est composé de plusieurs valeurs numériques spécifiées de la propriété du node.
Les intégrations finales des nodes cibles sont calculées à travers K itérations. Lors de l’itération k (k = 1,2,...,K), pour chaque node v ∈ Bk:
- Agréger les vecteurs de la (k-1)-ème des voisins échantillonnés pour obtenir un vecteur de voisinage, en utilisant la fonction d’agrégation AGGREGATEk.
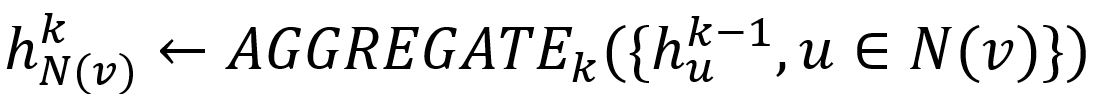
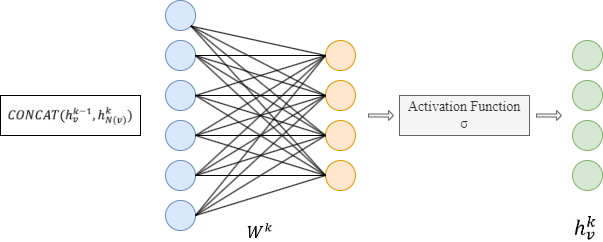
- Concaténer son vecteur (k-1) avec le vecteur de voisinage agrégé. Ce vecteur concaténé est ensuite affiné en passant par une couche entièrement connectée pondérée par la matrice Wk, suivie d'une fonction d’activation non linéaire σ (par exemple, Sigmoid, ReLu).
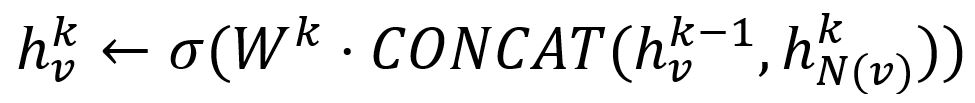
- Normaliser :
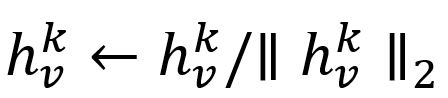
Le processus d'agrégation de caractéristiques de notre exemple peut être illustré comme suit :
| 1ère Itération | 2ème Itération |
|---|---|
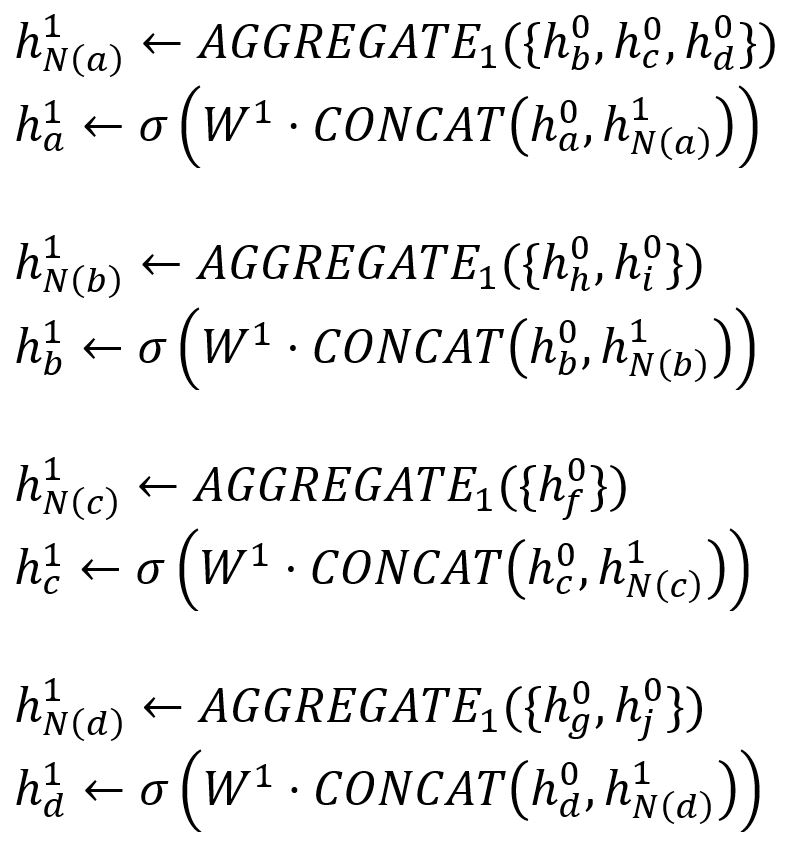 |
 |
Considérations
- L'algorithme GraphSAGE ignore la direction des edges mais les calcule comme des edges non dirigés.
Syntaxe
- Commande:
algo(graph_sage) - Paramètres:
Nom |
Type |
Spec |
Défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| model_task_id | int | / | / | Non | ID du task de l'algorithme GraphSAGE Train qui a entraîné le modèle |
| ids | []_id |
/ | / | Oui | ID des nodes pour générer des intégrations ; générer pour tous les nodes si non défini |
| node_property_names | []<property> |
Type numérique, doit LTE | Lu à partir du modèle | Oui | Propriétés du node pour former les vecteurs de caractéristiques |
| edge_property_name | <property> |
Type numérique, doit LTE | Lu à partir du modèle | Oui | Propriété de l'edge à utiliser comme poids d'edge ; edges sans poids si non défini |
| sample_size | []int | / | Lu à partir du modèle | Oui | Éléments de la liste sont le nombre de nodes échantillonnés à la couche K jusqu'à la couche 1 respectivement; la taille de la liste est le nombre de couches |
Exemples
Property Writeback
| Spec | Contenu | Écrire à | Type de donnée |
|---|---|---|---|
| property_name | Node embedding | Node property | string |
algo(graph_sage).params({
model_task_id: 4785,
ids: ['ULTIPA8000000000000001', 'ULTIPA8000000000000002']
}).write({
db:{
property_name: 'embedding_graphSage'
}
})
Résultats : L’intégration de chaque node est écrite sur une nouvelle propriété nommée embedding_graphSage