
Vue d’ensemble
L'algorithme de propagation de label (LPA) est un algorithme de détection de communautés utilisant la propagation de labels. Chaque node est initialisé avec un label et à chaque itération de l'algorithme, chaque node met à jour son label vers celui qui est le plus prévalent parmi ses voisins. Ce processus itératif permet aux groupes de nodes densément connectés de converger vers un consensus de labels, les nodes partageant le même label formant alors une communauté.
LPA n'optimise aucune mesure spécifique de la force des communautés et ne nécessite pas que le nombre de communautés soit prédéfini. Il exploite plutôt la structure du réseau pour guider sa progression. Cette simplicité permet à LPA d'analyser efficacement des réseaux grands et complexes.
Matériel connexe de l'algorithme :
- U.N. Raghavan, R. Albert, S. Kumara, Algorithme en temps presque linéaire pour détecter les structures de communauté dans les réseaux à grande échelle (2007)
Concepts
Label
Le label d'un node est initialisé avec une valeur de propriété spécifiée, ou son UUID unique.
Les nodes qui ont le même label à la fin de l'algorithme indiquent leur affiliation à une communauté commune.
Dans LPA, tous les labels initiaux sont valides et capables de se propager. Si certains labels doivent être définis comme invalides, veuillez contacter l'équipe Ultipa pour une personnalisation.
Propagation de Label
Dans les paramètres les plus simples, à chaque itération de propagation, chaque node met à jour son label vers celui auquel appartiennent le plus grand nombre de ses voisins.
Comme l'exemple suivant le montre, le label du node bleu sera mis à jour de d à c.
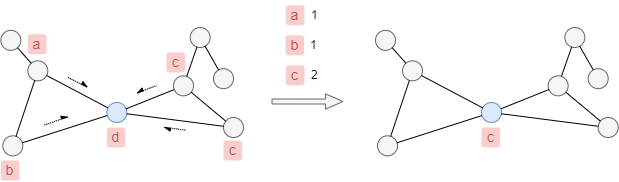
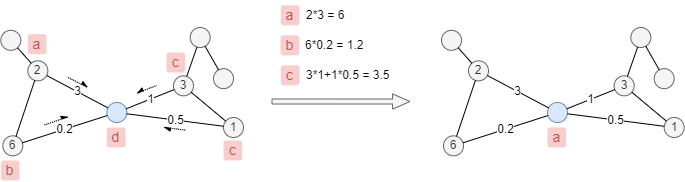
Lors de la prise en compte des poids des nodes et des edges, le poids du label équivaut à la somme des produits des poids correspondants des nodes et des edges, chaque node met à jour son label vers celui avec le poids le plus élevé.
Comme les poids des nodes et des edges indiqués dans l'exemple ci-dessous, le label du node bleu sera mis à jour de d à a.
Propagation Multi-label
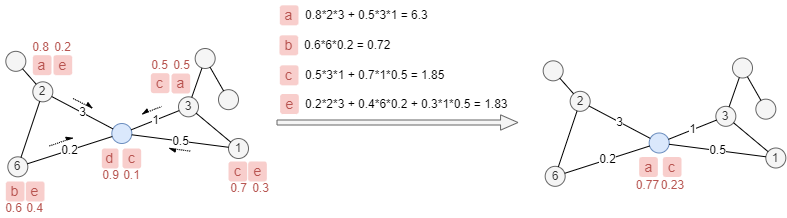
Dans la propagation multi-label, chaque node accepte plusieurs labels pendant la propagation. Dans ce cas, une probabilité de label proportionnelle à son poids est attribuée à chaque label d'un node, tandis que la somme des probabilités de labels de chaque node reste égale à 1.
Dans l'exemple ci-dessous, chaque node conserve 2 labels, les probabilités sont écrites à côté des labels, les labels du node bleu seront mis à jour de d, c à a, c avec des probabilités de labels Pa = 6.3/(6.3+1.85) = 0.77 et Pc = 1.85/(6.3+1.85) = 0.23.
Considérations
- LPA ignore la direction des edges mais les calcule comme des edges non dirigées.
- Un node avec des boucles se propage ses label(s) actuels à lui-même, et chaque boucle est comptée deux fois.
- LPA suit le principe de mise à jour synchrone lors de la mise à jour des labels des nodes. Cela signifie que tous les nodes mettent à jour leurs labels simultanément en fonction des labels de leurs voisins. Cependant, dans certains cas, des oscillations de labels peuvent se produire, en particulier dans les graphes bipartites. Pour résoudre ce problème, l'algorithme intègre un mécanisme d'interruption qui détecte et empêche les oscillations de labels excessives.
- En raison de facteurs tels que l'ordre des nodes, la sélection aléatoire des labels avec des poids égaux et les calculs parallèles, les résultats de division communautaire de LPA peuvent varier.
Syntaxe
- Commande :
algo(lpa) - Paramètres :
| Nom | Type |
Spéc |
Défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| node_label_property | @<schema>?.<property> |
Type Numérique/String, doit être LTE | / | Oui | Node property pour initialiser les labels des nodes, les nodes sans cette propriété ne sont pas impliqués dans la propagation de label; UUID est utilisé comme label pour tous les nodes si non défini |
| node_weight_property | @<schema>?.<property> |
Type Numérique, doit être LTE | / | Oui | Node property à utiliser comme poids de node |
| edge_weight_property | @<schema>?.<property> |
Type Numérique, doit être LTE | / | Oui | Edge property à utiliser comme poids de edge |
| loop_num | int | ≥1 | 5 |
Oui | Nombre d'itérations de propagation |
| k | int | ≥1 | 1 |
Oui | Nombre maximum de labels que chaque node conserve à la fin (tous les labels sont ordonnés par leur probabilité de la plus élevée à la plus basse) |
Exemples
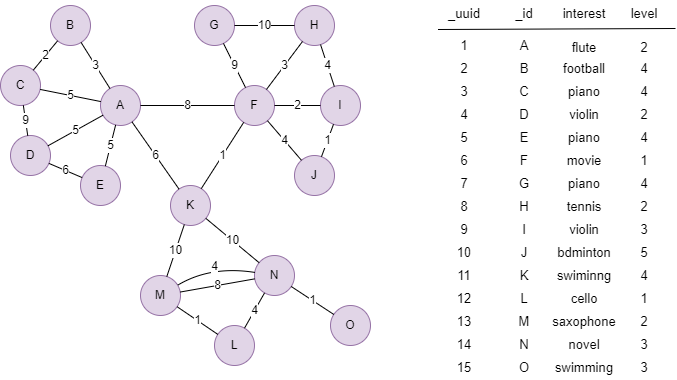
Le graph d'exemple est le suivant, les nodes sont de schema user, les edges sont de schema connect, la valeur de @connect.strength est indiquée dans le graph :
File Writeback
Spéc |
Contenu |
|---|---|
| filename | _id,label_1,probability_1,...label_k,probability_k |
algo(lpa).params({
k: 2,
loop_num: 5,
edge_weight_property: 'strength'
}).write({
file:{
filename: "lpa"
}
})
Statistiques : label_count = 7
Résultats : Fichier lpa
O,1,0.599162,2,0.400838,
N,1,0.634582,2,0.365418,
M,1,0.610834,2,0.389166,
L,1,0.607434,2,0.392566,
K,1,0.619842,2,0.380158,
J,14,0.655975,8,0.344025,
I,14,0.546347,8,0.453653,
H,9,0.690423,7,0.309577,
G,14,0.569427,8,0.430573,
F,9,0.784132,7,0.215869,
E,9,0.519003,12,0.480997,
D,14,0.781072,9,0.218928,
C,12,0.540345,9,0.459655,
B,9,0.559427,14,0.440573,
A,14,0.768171,12,0.231829,
Property Writeback
Spéc |
Contenu | Écrire à |
Type de Donnée |
|---|---|---|---|
| property | label_1, probability_1, ... label_k, probability_k |
Node property | Label: string,Probabilité de Label: float |
algo(lpa).params({
node_label_property: 'interest',
edge_weight_property: '@connect.strength',
k: 2,
loop_num: 10
}).write({
db:{
property: "lab"
}
})
Statistiques : label_count = 5
Résultats : Les labels et la probabilité correspondante de chaque node sont écrits dans de nouvelles propriétés lab_1, probability_1, lab_2 et probability_2 respectivement
Direct Return
Alias Ordinal |
Type |
Description |
Colonnes |
|---|---|---|---|
| 0 | []perNode | Node et ses labels, probabilités de labels | _uuid, label_1, probability_1, ... label_k, probability_k |
| 1 | KV | Nombre de labels | label_count |
algo(lpa).params({
node_label_property: '@user.interest',
node_weight_property: '@user.level'
}) as res
return res
Résultats : res
| _uuid | label_1 | probability_1 |
|---|---|---|
| 15 | novel | 1.000000 |
| 14 | swimming | 1.000000 |
| 13 | novel | 1.000000 |
| 12 | novel | 1.000000 |
| 11 | novel | 1.000000 |
| 10 | violin | 1.000000 |
| 9 | badminton | 1.000000 |
| 8 | piano | 1.000000 |
| 7 | badminton | 1.000000 |
| 6 | badminton | 1.000000 |
| 5 | piano | 1.000000 |
| 4 | piano | 1.000000 |
| 3 | piano | 1.000000 |
| 2 | piano | 1.000000 |
| 1 | piano | 1.000000 |
algo(lpa).params({
node_label_property: 'interest',
k: 2
}) as res, stats
return res, stats
Résultats : res et stats
| _uuid | label_1 | probability_1 | label_2 | probability_2 |
|---|---|---|---|---|
| 15 | novel | 0.642453 | saxophone | 0.357547 |
| 14 | swimming | 0.577773 | saxophone | 0.422227 |
| 13 | novel | 0.610180 | swimming | 0.389820 |
| 12 | saxophone | 0.608193 | novel | 0.391807 |
| 11 | piano | 0.536380 | saxophone | 0.463620 |
| 10 | piano | 0.588276 | movie | 0.411724 |
| 9 | piano | 0.595449 | movie | 0.404551 |
| 8 | piano | 0.637065 | movie | 0.362935 |
| 7 | piano | 0.554655 | movie | 0.445345 |
| 6 | piano | 0.720096 | movie | 0.279904 |
| 5 | piano | 0.502892 | flute | 0.497108 |
| 4 | piano | 0.648339 | flute | 0.351661 |
| 3 | piano | 0.520442 | flute | 0.479558 |
| 2 | piano | 0.624170 | flute | 0.375831 |
| 1 | piano | 0.670773 | flute | 0.329227 |
| label_count |
|---|
| 6 |
Stream Return
Alias Ordinal |
Type |
Description |
Colonnes |
|---|---|---|---|
| 0 | []perNode | Node et ses labels, probabilités de labels | _uuid, label_1, probability_1, ... label_k, probability_k |
algo(lpa).params({
node_label_property: '@user.interest',
node_weight_property: '@user.level',
edge_weight_property: 'strength',
loop_num: 10
}).stream() as lpa
group by lpa.label_1
with count(lpa) as labelCount
return table(lpa.label_1, labelCount)
order by labelCount desc
Résultats : table(lpa.label_1, labelCount)
| lpa.label_1 | labelCount |
|---|---|
| piano | 5 |
| swimming | 3 |
| violin | 2 |
| novel | 2 |
| tennis | 2 |
Stats Return
Alias Ordinal |
Type |
Description | Colonnes |
|---|---|---|---|
| 0 | KV | Nombre de labels | label_count |
algo(lpa).params({
node_label_property: 'interest',
edge_weight_property: 'strength',
k: 1,
loop_num: 5
}).stats() as count
return count
Résultats : count
| label_count |
|---|
| 5 |