
Vue d’ensemble
Node2Vec est un algorithme semi-supervisé conçu pour l'apprentissage de caractéristiques des nodes dans les graphs tout en préservant efficacement leurs voisinages. Il introduit une stratégie de recherche polyvalente qui peut explorer les voisinages BFS et DFS des nodes. Il étend également le modèle Skip-gram aux graphs pour entraîner les embeddings des nodes. Node2Vec a été développé par A. Grover et J. Leskovec à l'Université de Stanford en 2016.
- A. Grover, J. Leskovec, node2vec: Scalable Feature Learning for Networks (2016)
Concepts
Similarité des Nodes
Node2Vec apprend une correspondance des nodes dans un espace vectoriel de faible dimension, visant à s'assurer que les nodes similaires dans le réseau présentent des embeddings proches dans l'espace vectoriel.
Les nodes dans un réseau alternent souvent entre deux types de similarités :
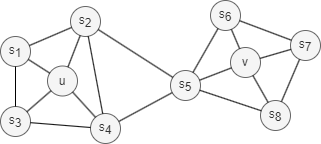
1. Homophilie
L'homophilie dans les réseaux fait référence au phénomène selon lequel les nodes ayant des propriétés, caractéristiques ou comportements similaires sont plus susceptibles d'être connectés ensemble ou d'appartenir aux mêmes communautés ou à des communautés similaires (les nodes u et s1 dans le graph ci-dessus appartiennent à la même communauté).
Par exemple, dans les réseaux sociaux, les individus ayant des origines, des intérêts ou des opinions similaires sont plus susceptibles de former des connexions.
2. Équivalence Structurelle
L'équivalence structurelle dans les réseaux fait référence au concept où les nodes sont considérés comme équivalents en fonction de leurs rôles structurels au sein du réseau. Les nodes qui sont structurellement équivalents présentent des schémas de connectivité et des relations similaires avec d'autres nodes (i.e., la topologie locale), même si leurs caractéristiques individuelles sont différentes (les nodes u et v dans le graph ci-dessus agissent comme des hubs de leurs communautés correspondantes).
Par exemple, dans les réseaux sociaux, les individus qui sont structurellement équivalents pourraient occuper des positions similaires dans leurs groupes sociaux.
Contrairement à l'homophilie, l'équivalence structurelle ne met pas l'accent sur la connectivité ; les nodes pourraient être éloignés dans le réseau et avoir encore le même rôle structurel.
Lorsqu'on discute de l'équivalence structurelle, il est important de garder à l'esprit deux points clés : Premièrement, atteindre une équivalence structurelle complète dans un réseau réel est rare, ce qui nous amène à nous concentrer sur l'évaluation de la similarité structurelle à la place. Deuxièmement, à mesure que l'étendue du voisinage analysé s'élargit, le niveau de similarité structurelle entre les deux nodes a tendance à diminuer.
Stratégies de Recherche
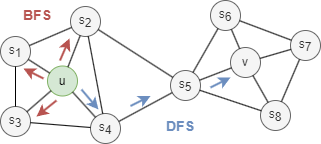
Généralement, il existe deux stratégies de recherche extrêmes pour générer un ensemble de voisinage NS de k nodes :
- Recherche en largeur (BFS): NS est limité aux nodes qui sont des voisins immédiats du node de départ. Par exemple, NS(u) = s1, s2, s3 de taille k = 3 dans le graph ci-dessus.
- Recherche en profondeur (DFS): NS est composé de nodes recherchés séquentiellement à des distances croissantes du node de départ. Par exemple, NS(u) = s4, s5, v de taille k = 3 dans le graph ci-dessus.
Les stratégies BFS et DFS jouent un rôle clé dans la production d'embeddings qui reflètent l'homophilie ou l'équivalence structurelle entre les nodes :
- Les voisinages échantillonnés par BFS conduisent à des embeddings qui correspondent étroitement à l'équivalence structurelle. En limitant la recherche aux nodes proches, BFS obtient une vue microscopique du voisinage qui est souvent suffisante pour caractériser la topologie locale.
- Les voisinages échantillonnés par DFS conduisent à des embeddings qui correspondent étroitement à l'homophilie. En s'éloignant du node de départ, DFS obtient une vue macroscopique du voisinage qui est essentielle pour déduire les dépendances node-à-node existent dans une communauté.
Cadre Node2Vec
1. Marche Node2Vec
Node2Vec emploie une marche aléatoire biaisée avec le paramètre de retour p et le paramètre d'in-out q pour guider la marche.
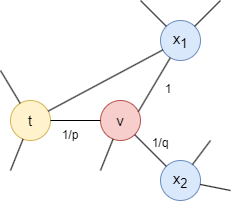
Considérons la marche aléatoire qui vient de traverser l'edge (t,v) et qui arrive maintenant au node v, la prochaine étape de la marche est déterminée par les probabilités de transition sur les edges (v,x) originaires de v, qui sont proportionnelles aux poids des edges (les poids sont de 1 dans les graphs non pondérés). Les poids des edges (v,x) sont ajustés par p et q en fonction de la distance la plus courte dtx entre les nodes t et x :
- Si dtx = 0, le poids de l'edge est ajusté par
1/p. Dans le graph fourni, dtt = 0. Le paramètrepinfluence l'inclination à revisiter le node qui vient d'être quitté. Quandp< 1, revenir en arrière d'un pas devient plus probable; quandp> 1, autrement. - Si dtx = 1, le poids de l'edge reste inchangé. Dans le graph fourni, dtx1 = 1.
- Si dtx = 2, le poids de l'edge est ajusté par
1/q. Dans le graph fourni, dtx2 = 2. Le paramètreqdétermine si la marche se déplace vers l'intérieur (q> 1) ou vers l'extérieur (q< 1).
Notez que dtx doit être l'un de {0, 1, 2}.
Grâce aux deux paramètres, Node2Vec offre un moyen de contrôler le compromis entre exploration et exploitation lors de la génération de marches aléatoires, ce qui conduit à des représentations obéissant à un spectre d'équivalences allant de l'homophilie à l'équivalence structurelle.
2. Embeddings des Nodes
Les séquences de nodes obtenues à partir des marches aléatoires servent d'entrée au modèle Skip-gram. SGD est utilisé pour optimiser les paramètres du modèle en fonction de l'erreur de prédiction, et le modèle est optimisé par des techniques telles que l'échantillonnage négatif et le sous-échantillonnage.
Considérations
- L'algorithme Node2Vec ignore la direction des edges mais les calcule comme des edges non orientés.
Syntaxe
- Commande:
algo(node2vec) - Paramètres :
Nom |
Type |
Spéc |
Par défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| ids / uuids | []_id / []_uuid |
/ | / | Oui | ID/UUID des nodes pour commencer les marches aléatoires; commence de tous les nodes si non défini |
| walk_length | int | ≥1 | 1 |
Oui | Profondeur de chaque marche, i.e., le nombre de nodes à visiter |
| walk_num | int | ≥1 | 1 |
Oui | Nombre de marches à effectuer pour chaque node spécifié |
| edge_schema_property | []@<schema>?.<property> |
Type numérique, doit être LTE | / | Oui | Propriété(-és) d'edge à utiliser comme poids d'edge(s), où les valeurs de plusieurs propriétés sont additionnées ; les nodes ne marchent que le long des edges avec la propriété(-és) spécifiée |
| p | float | >0 | 1 |
Oui | Le paramètre de retour; une valeur plus grande réduit la probabilité de retour |
| q | float | >0 | 1 |
Oui | Le paramètre in-out; il tend à marcher au même niveau lorsque la valeur est supérieure à 1, sinon il tend à s'éloigner |
| window_size | int | ≥1 | / | Non | La taille maximale du contexte |
| dimension | int | ≥2 | / | Non | Dimensionnalité des embeddings |
| loop_num | int | ≥1 | / | Non | Nombre d'itérations d'entraînement |
| learning_rate | float | (0,1) | / | Non | Taux d'apprentissage utilisé initialement pour entraîner le modèle, qui diminue après chaque itération d'entraînement jusqu'à atteindre min_learning_rate |
| min_learning_rate | float | (0,learning_rate) |
/ | Non | Seuil minimal pour le taux d'apprentissage car il est progressivement réduit pendant l'entraînement |
| neg_num | int | ≥0 | / | Non | Nombre d'échantillons négatifs à produire pour chaque échantillon positif, il est suggéré de le définir entre 0 et 10 |
| resolution | int | ≥1 | 1 |
Oui | Le paramètre utilisé pour améliorer l'efficacité de l'échantillonnage négatif; une valeur plus élevée offre une meilleure approximation de la distribution de bruit originale; il est suggéré de le régler à 10, 100, etc. |
| sub_sample_alpha | float | / | 0.001 |
Oui | Le facteur influençant la probabilité de sous-échantillonnage des nodes fréquents; une valeur plus élevée augmente cette probabilité; une valeur ≤0 signifie ne pas appliquer de sous-échantillonnage |
| min_frequency | int | / | / | Non | Les nodes qui apparaissent moins de fois que ce seuil dans le "corpus" d'entraînement seront exclus du "vocabulaire" et ignorés dans l'entraînement des embeddings; une valeur ≤0 signifie garder tous les nodes |
| limit | int | ≥-1 | -1 |
Oui | Nombre de résultats à retourner, -1 pour retourner tous les résultats |
Exemple
File Writeback
| Spéc | Contenu |
|---|---|
| filename | _id,embedding_result |
algo(node2vec).params({
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
buffer_size: 1000,
window_size: 5,
dimension: 20,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}).write({
file:{
filename: 'embeddings'
}})
Property Writeback
| Spéc | Contenu | Écrire vers | Type de Données |
|---|---|---|---|
| property | embedding_result |
Node Property | string |
algo(node2vec).params({
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
buffer_size: 1000,
window_size: 5,
dimension: 20,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}).write({
db:{
property: 'vector'
}})
Direct Return
| Ordinal Alias | Type |
Description |
Colonnes |
|---|---|---|---|
| 0 | []perNode | Node et ses embeddings | _uuid, embedding_result |
algo(node2vec).params({
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
buffer_size: 1000,
window_size: 5,
dimension: 20,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}) as embeddings
return embeddings
Stream Return
| Ordinal Alias | Type |
Description |
Colonnes |
|---|---|---|---|
| 0 | []perNode | Node et ses embeddings | _uuid, embedding_result |
algo(node2vec).params({
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
buffer_size: 1000,
window_size: 5,
dimension: 20,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}).stream() as embeddings
return embeddings