
Vue d’ensemble
Le coefficient de corrélation de Pearson est la méthode la plus courante pour mesurer la force et la direction de la relation linéaire entre deux variables quantitatives. Dans le graph, les nodes sont quantifiés par N propriétés numériques (caractéristiques) de ceux-ci.
Pour deux variables X= (x1, x2, ..., xn) et Y = (y1, y2, ..., yn), le coefficient de corrélation de Pearson (r) est défini comme le rapport de leur covariance et le produit de leurs écarts-types :
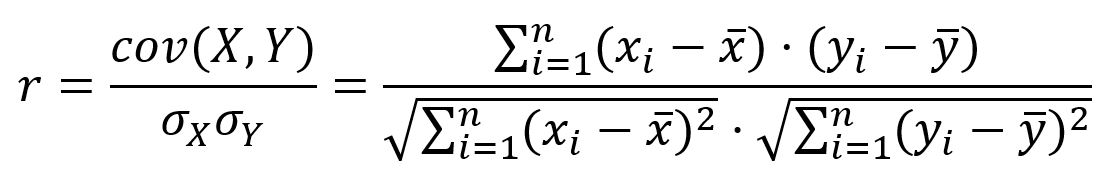
Le coefficient de corrélation de Pearson varie de -1 à 1 :
Coefficient de corrélation de Pearson |
Type de corrélation |
Interprétation |
|---|---|---|
| 0 < r ≤ 1 | Corrélation positive | Comme une variable devient plus grande, l'autre variable devient plus grande |
| r = 0 | Aucune corrélation linéaire | (Il peut exister d'autres types de corrélation) |
| -1 ≤ r < 0 | Corrélation négative | Comme une variable devient plus grande, l'autre variable devient plus petite |
Considérations
- Théoriquement, le calcul du coefficient de corrélation de Pearson entre deux nodes ne dépend pas de leur connectivité.
Syntaxe
- Commande :
algo(similarity) - Paramètres :
Nom |
Type |
Spécification |
Défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| ids / uuids | []_id / []_uuid |
/ | / | Non | ID/UUID du premier groupe de nodes à calculer |
| ids2 / uuids2 | []_id / []_uuid |
/ | / | Oui | ID/UUID du second groupe de nodes à calculer |
| type | string | pearson |
cosine |
Non | Type de similarité ; pour le coefficient de corrélation de Pearson, laisser comme pearson |
| node_schema_property | []@<schema>?.<property> |
Type numérique, doit être LTE | / | Non | Spécifiez deux propriétés de node ou plus pour former les vecteurs, toutes les propriétés doivent appartenir au même (un) schema |
| limit | int | ≥-1 | -1 |
Oui | Nombre de résultats à retourner, -1 pour retourner tous les résultats |
| top_limit | int | ≥-1 | -1 |
Oui | En mode sélection, limite le nombre maximum de résultats retournés pour chaque node spécifié dans ids/uuids, -1 pour retourner tous les résultats avec similarité > 0 ; en mode pairage, ce paramètre est invalide |
L'algorithme a deux modes de calcul :
- Pairage : quand à la fois
ids/uuidsetids2/uuids2sont configurés, associer chaque node dansids/uuidsavec chaque node dansids2/uuids2(ignorer le même node) et calculer les similitudes par paires. - Sélection : quand seulement
ids/uuidsest configuré, pour chaque node cible, calculer les similitudes par paires entre lui et tous les autres nodes du graph. Les résultats retournés incluent tous les nodes ou un nombre limité de nodes qui ont une similarité > 0 avec le node cible et sont ordonnés par similarité décroissante.
Exemples
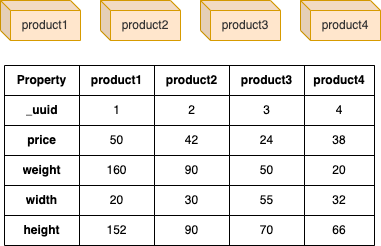
Le graph d'exemple a 4 produits (les edges sont ignorés), chaque produit a des propriétés price, weight, weight et height :
File Writeback
| Spécification | Contenu |
|---|---|
| filename | node1,node2,similarity |
algo(similarity).params({
uuids: [1],
uuids2: [2,3,4],
node_schema_property: ['price', 'weight', 'width', 'height'],
type: 'pearson'
}).write({
file:{
filename: 'pearson'
}
})
Résultats : Fichier pearson
product1,product2,0.998785
product1,product3,0.474384
product1,product4,0.210494
algo(similarity).params({
uuids: [1,2,3,4],
node_schema_property: ['price', 'weight', 'width', 'height'],
type: 'pearson'
}).write({
file:{
filename: 'list'
}
})
Résultats : Fichier list
product1,product2,0.998785
product1,product3,0.474384
product1,product4,0.210494
product2,product1,0.998785
product2,product3,0.507838
product2,product4,0.253573
product3,product2,0.507838
product3,product1,0.474384
product3,product4,0.474021
product4,product3,0.474021
product4,product2,0.253573
product4,product1,0.210494
Direct Return
Alias Ordinal |
Type |
Description | Colonnes |
|---|---|---|---|
| 0 | []perNodePair | Paire de nodes et sa similarité | node1, node2, similarity |
algo(similarity).params({
uuids: [1,2],
uuids2: [2,3,4],
node_schema_property: ['price', 'weight', 'width', 'height'],
type: 'pearson'
}) as p
return p
Résultats : p
| node1 | node2 | similarity |
|---|---|---|
| 1 | 2 | 0.998785121601255 |
| 1 | 3 | 0.474383803132863 |
| 1 | 4 | 0.210494150169583 |
| 2 | 3 | 0.50783775659896 |
| 2 | 4 | 0.253573071269506 |
algo(similarity).params({
uuids: [1,2],
type: 'pearson',
node_schema_property: ['price', 'weight', 'width', 'height'],
top_limit: 1
}) as top
return top
Résultats : top
| node1 | node2 | similarity |
|---|---|---|
| 1 | 2 | 0.998785121601255 |
| 2 | 1 | 0.998785121601255 |
Stream Return
Alias Ordinal |
Type |
Description | Colonnes |
|---|---|---|---|
| 0 | []perNodePair | Paire de nodes et sa similarité | node1, node2, similarity |
algo(similarity).params({
uuids: [3],
uuids2: [1,2,4],
node_schema_property: ['@product.price', '@product.weight', '@product.width'],
type: 'pearson'
}).stream() as p
where p.similarity > 0
return p
Résultats : p
| node1 | node2 | similarity |
|---|---|---|
| 3 | 1 | 0.167101674410905 |
| 3 | 2 | 0.181677473801374 |
algo(similarity).params({
uuids: [1,3],
node_schema_property: ['price', 'weight', 'width', 'height'],
type: 'pearson',
top_limit: 1
}).stream() as top
return top
Résultats : top
| node1 | node2 | similarity |
|---|---|---|
| 1 | 2 | 0.998785121601255 |
| 3 | 2 | 0.50783775659896 |