
Vue d’ensemble
L'attachement préférentiel est un phénomène courant dans les réseaux complexes où les nodes avec plus de connexions sont plus susceptibles d'établir de nouvelles connexions. Lorsque les deux nodes possèdent un grand nombre de connexions, la probabilité qu'ils forment une connexion est significativement plus élevée. Ce phénomène a été utilisé par A. Barabási et R. Albert dans leur modèle BA proposé pour générer des réseaux aléatoires sans échelle en 2002 :
- R. Albert, A. Barabási, Statistical mechanics of complex networks (2001)
L'algorithme de l'Attachement Préférentiel évalue la similarité entre deux nodes en calculant le produit du nombre de voisins que chaque node a. Il est calculé en utilisant la formule suivante :
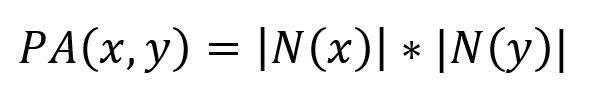
où N(x) et N(y) sont les ensembles de nodes adjacents aux nodes x et y respectivement.
Des scores d'Attachement Préférentiel plus élevés indiquent une plus grande similarité entre les nodes, tandis qu'un score de 0 indique une absence de similarité entre deux nodes.
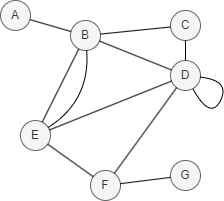
Dans cet exemple, PA(D,E) = |N(D)| * |N(E)| = |{B, C, E, F}| * |{B, D, F}| = 4 * 3 = 12.
Considérations
- L'algorithme de l'Attachement Préférentiel ignore la direction des edges mais les calcule comme des edges non dirigés.
Syntaxe
- Commande :
algo(topological_link_prediction) - Paramètres :
Nom |
Type |
Spéc |
Défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| ids / uuids | []_id / []_uuid |
/ | / | No | ID/UUID du premier ensemble de nodes à calculer; chaque node dans ids/uuids sera jumelé avec chaque node dans ids2/uuids2 |
| ids2 / uuids2 | []_id / []_uuid |
/ | / | No | ID/UUID du second ensemble de nodes à calculer; chaque node dans ids/uuids sera jumelé avec chaque node dans ids2/uuids2 |
| type | string | Preferential_Attachment |
Adamic_Adar |
No | Type de similarité; pour l'Attachement Préférentiel, gardez-le comme Preferential_Attachment |
| limit | int | >=-1 | -1 |
Yes | Nombre de résultats à retourner, -1 pour retourner tous les résultats |
Exemple
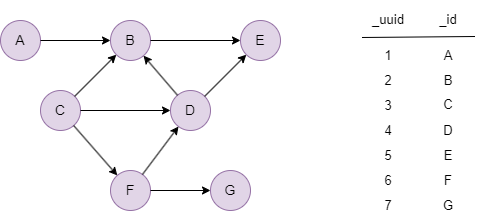
Le graph d'exemple est le suivant :
File Writeback
| Spéc | Contenu |
|---|---|
| filename | node1,node2,num |
algo(topological_link_prediction).params({
uuids: [3],
uuids2: [1,5,7],
type: 'Preferential_Attachment'
}).write({
file:{
filename: 'pa'
}
})
Résultats: Fichier pa
C,A,3.000000
C,E,6.000000
C,G,3.000000
Direct Return
| Ordre Alias | Type | Description |
Colonnes |
|---|---|---|---|
| 0 | []perNodePair | Node pair et sa similarité | node1, node2, num |
algo(topological_link_prediction).params({
ids: 'C',
ids2: ['A','C','E','G'],
type: 'Preferential_Attachment'
}) as pa
return pa
Résultats: pa
| node1 | node2 | num |
|---|---|---|
| 3 | 1 | 3 |
| 3 | 5 | 6 |
| 3 | 7 | 3 |
Stream Return
| Ordre Alias | Type | Description |
Colonnes |
|---|---|---|---|
| 0 | []perNodePair | Node pair et sa similarité | node1, node2, num |
find().nodes() as n
with collect(n._id) as nID
algo(topological_link_prediction).params({
ids: 'C',
ids2: nID,
type: 'Preferential_Attachment'
}).stream() as pa
where pa.num >= 2
return pa
Résultats: pa
| node1 | node2 | num |
|---|---|---|
| 3 | 2 | 12 |
| 3 | 4 | 12 |
| 3 | 5 | 6 |
| 3 | 6 | 9 |