
Vue d’ensemble
Struc2Vec signifie "structure en vecteur". Cet algorithme révolutionne les embeddings de graph par la génération de vecteurs de node tout en conservant la structure inhérente du graph, se concentrant sur la préservation des similitudes topologiques.
- L. Ribeiro, P. Saverese, D. Figueiredo, struc2vec: Learning Node Representations from Structural Identity (2017)
Tandis que Node2Vec capture un certain degré de similarité structurelle parmi les nodes, il est limité par la profondeur des marches aléatoires utilisées lors du processus de génération. En revanche, Struc2Vec surmonte cette limitation dans son cadre. Il veille à ce que les nodes aux caractéristiques structurelles similaires soient représentés proches l'un de l'autre dans l'espace d'embedding.
Le choix entre Node2Vec et Struc2Vec dépend de la nature des tâches en aval :
- Node2Vec convient aux tâches priorisant l'homophilie des nodes, capturant la similarité dans les attributs et connexions.
- Struc2Vec excelle lorsque les tâches exigent une concentration sur la similarité topologique locale, préservant les relations structurelles parmi les nodes.
Concepts
Similarité Structurelle
Dans divers réseaux, les nodes possèdent souvent des identités structurelles distinctes façonnées par leurs fonctions ou rôles spécifiques. Les nodes exécutant des fonctions similaires appartiennent naturellement à la même classe, signifiant leur similarité structurelle. Par exemple, dans un réseau social d'une entreprise, tous les stagiaires peuvent présenter des rôles similaires.
La similarité structurelle parmi les nodes implique que leurs topologies de voisinage sont homogènes ou symétriques. Cela indique que les nodes avec des fonctions similaires ont des connexions et relations analogues avec leurs nodes voisins.

Comme illustré ici, les nodes u et v sont structurellement similaires (degrés 5 et 4, connectés à 3 et 2 triangles, connectés au reste du réseau par 2 nodes). Bien qu'ils n'aient pas de lien direct ou de voisin commun, et qu'ils puissent être très éloignés dans le réseau.
Lorsque la distance entre les nodes dépasse la profondeur des marches aléatoires, il devient difficile de générer des représentations similaires pour eux en utilisant des méthodes comme Node2Vec. Cette limitation est efficacement abordée par l'algorithme Struc2Vec.
Cadre Struc2Vec
1. Mesurer la similarité structurelle
Intuitivement, deux nodes qui ont les mêmes degrés sont considérés structurellement similaires, mais si leurs voisins ont également le même degré, alors ils sont encore plus structurellement similaires.
Considérons un graph non-orienté et non pondéré G = (V, E), son diamètre est noté comme k*. Soit Rk(u) l'ensemble des nodes situés à une distance exacte (nombre de sauts) de k ∈ [0, k*] à partir du node u dans G. Soit s(S) la séquence de degrés ordonnée d'un ensemble de nodes S ⊂ V. Voici un exemple :
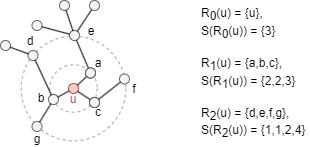
Soit fk(u,v) la distance structurelle entre u et v lorsqu'on considère leurs voisinages de k-saut (tous les nodes à une distance inférieure ou égale à k) :
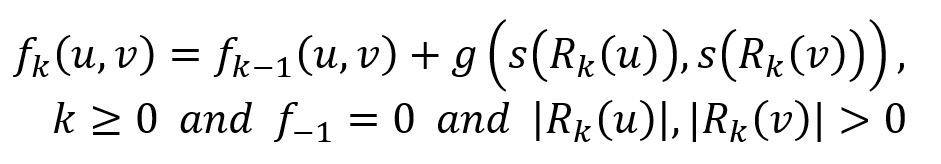
où la fonction g() ≥ 0 mesure la distance entre deux séquences de degrés. Notez que fk(u,v) est non décroissant en k et n'est défini que lorsque u et v ont des voisins à distance k.
Pour évaluer la distance entre les séquences s(Rk(u)) et s(Rk(v)), qui peuvent être de tailles différentes, le Dynamic Time Wrapping (DTW), ou toute autre fonction applicable, peut être adopté. Notez que si les voisinages de k-saut des nodes u et v sont isomorphes, alors fk-1(u,v) = 0.
2. Construire un graph pondéré multicouche
Struc2Vec construit un graph pondéré multicouche M qui encode la similarité structurelle entre les nodes, où la couche k est définie à l'aide des voisinages de k-saut des nodes.
Chaque couche k est formée par un graph non orienté et complet pondéré avec un ensemble de nodes V, et donc arêtes. Le poids de l'arête entre les nodes u et v est inversement proportionnel à leur distance structurelle, comme indiqué par :
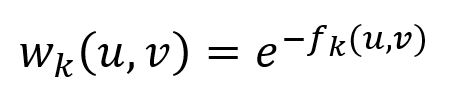
Notez que les arêtes sont définies uniquement si fk(u,v) est défini.
Les couches sont connectées par des arêtes dirigées. Chaque node est connecté à son node correspondant dans la couche au-dessus et en dessous (couche permettant), et le poids de l'arête entre les couches est le suivant :
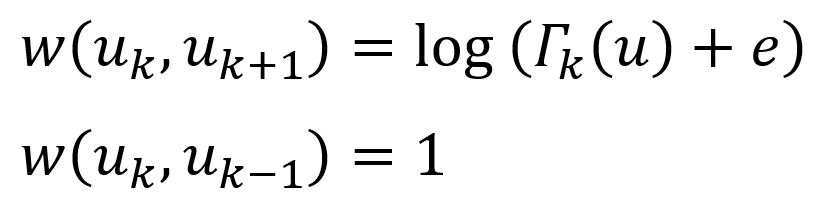
où Γk(u) est le nombre d'arêtes incidentes à u qui ont un poids supérieur au poids moyen des arêtes du graph complet dans la couche k. Γk(u) mesure en réalité la similarité du node u avec d'autres nodes dans la couche k. Notez que si le node u a beaucoup de nodes similaires dans la couche k, alors il devrait monter vers des couches supérieures pour obtenir un contexte plus raffiné.
3. Générer un contexte pour les nodes
Struc2Vec utilise des marches aléatoires pour générer une séquence de nodes afin de déterminer le contexte d'un node donné.
Considérons une marche aléatoire biaisée qui se déplace dans le graph M. Chaque node commence la marche dans son node correspondant dans la couche 0, et lorsqu'il atteint le node u dans la couche k (noté uk), la marche aléatoire décide d'abord si elle va (1) rester dans la couche actuelle, ou (2) changer de couche :
(1) Avec une probabilité q, la marche aléatoire reste dans la couche actuelle : la probabilité de passer à vk est proportionnelle à wk(u,v). Notez que la marche aléatoire préférera se déplacer vers les nodes qui sont structurellement plus similaires au node actuel.
(2) Avec une probabilité 1 − q, la marche aléatoire change de couche : les probabilités de passer à uk+1 ou uk-1 sont proportionnelles à wk(uk,uk+1) et wk(uk,uk-1). Il est important de noter que dans ce cas, le node u est enregistré seulement une fois dans la séquence de la marche aléatoire.
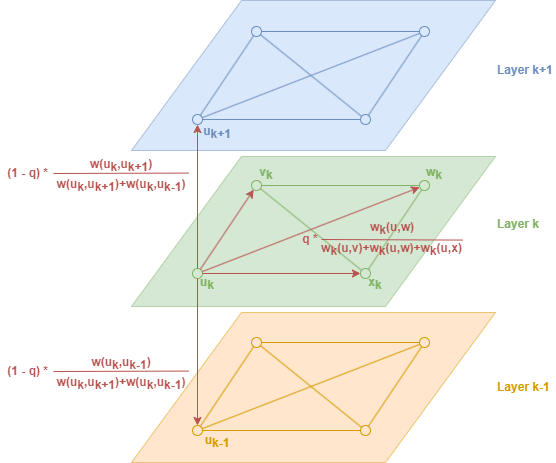
Les marches aléatoires ont une profondeur fixe et relativement courte (nombre d'étapes), et le process est répété un certain nombre de fois.
4. Entraîner le modèle
Les séquences de nodes obtenues à partir des marches aléatoires servent d'entrée au modèle Skip-gram. SGD est utilisé pour optimiser les paramètres du modèle basés sur l'erreur de prédiction, et le modèle est optimisé par des techniques telles que l'échantillonnage négatif et le sous-échantillonnage.
Considérations
- Lors de la prise en compte du degré d'un node, toute boucle est comptée deux fois.
- L'algorithme Struc2Vec ignore la direction des arêtes mais les calcule comme des arêtes non orientées.
Syntaxe
- Commande:
algo(struc2vec) - Paramètre :
Nom |
Type |
Spécification |
Défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| ids / uuids | []_id / []_uuid |
/ | / | Oui | ID/UUID des nodes pour débuter les marches aléatoires ; commencez par tous les nodes si non défini |
| walk_length | int | ≧1 | 1 |
Oui | Profondeur de chaque marche, c'est-à-dire le nombre de nodes à visiter |
| walk_num | int | ≧1 | 1 |
Oui | Nombre de marches à effectuer pour chaque node spécifié |
| k | int | [1, 10] | / | Non | Nombre de couches du graph pondéré multicouche construit, qui ne doit pas dépasser le diamètre du graph original |
| stay_probability | float | (0,1] | / | Non | La probabilité de marcher dans le niveau actuel |
| window_size | int | ≥1 | / | Non | La taille maximale du contexte |
| dimension | int | ≥2 | / | Non | Dimensionalité des embeddings |
| loop_num | int | ≥1 | / | Non | Nombre d'itérations d'entraînement |
| learning_rate | float | (0,1) | / | Non | Taux d'apprentissage utilisé initialement pour entraîner le modèle, qui diminue après chaque itération d'entraînement jusqu'à atteindre min_learning_rate |
| min_learning_rate | float | (0,learning_rate) |
/ | Non | Seuil minimum pour le taux d'apprentissage car il est progressivement réduit pendant l'entraînement |
| neg_num | int | ≥0 | / | Non | Nombre d'échantillons négatifs à produire pour chaque échantillon positif, il est suggéré de régler entre 0 et 10 |
| resolution | int | ≥1 | 1 |
Oui | Le paramètre utilisé pour améliorer l'efficacité de l'échantillonnage négatif ; une valeur plus élevée offre une meilleure approximation de la distribution de bruit originale ; il est suggéré de le fixer à 10, 100, etc. |
| sub_sample_alpha | float | / | 0.001 |
Oui | Le facteur affectant la probabilité de sous-échantillonnage des nodes fréquents ; une valeur plus élevée augmente cette probabilité ; une valeur ≤0 signifie ne pas appliquer de sous-échantillonnage |
| min_frequency | int | / | / | Non | Les nodes qui apparaissent moins de fois que ce seuil dans le "corpus" d'entraînement seront exclus du "vocabulaire" et ignorés lors de l'entraînement des embeddings ; une valeur ≤000 signifie garder tous les nodes |
| limit | int | ≥-1 | -1 |
Oui | Nombre de résultats à retourner, -1 pour retourner tous les résultats |
Exemple
File Writeback
| Spécification | Contenu |
|---|---|
| filename | _id,embedding_result |
algo(struc2vec).params({
walk_length: 10,
walk_num: 20,
k: 10,
stay_probability: 0.4,
window_size: 5,
dimension: 20,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}).write({
file:{
filename: 'embeddings'
}})
Property Writeback
| Spécification | Contenu | Écrire dans | Type de Donnée |
|---|---|---|---|
| property | embedding_result |
Propriété du node | string |
algo(struc2vec).params({
walk_length: 10,
walk_num: 20,
k: 10,
stay_probability: 0.4,
window_size: 5,
dimension: 20,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}).write({
db:{
property: 'vector'
}})
Direct Return
| Alias Ordinal | Type |
Description |
Colonnes |
|---|---|---|---|
| 0 | []par Node | Node et ses embeddings | _uuid, embedding_result |
algo(struc2vec).params({
walk_length: 10,
walk_num: 20,
k: 10,
stay_probability: 0.4,
window_size: 5,
dimension: 20,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}) as embeddings
return embeddings
Stream Return
| Alias Ordinal | Type |
Description |
Colonnes |
|---|---|---|---|
| 0 | []par Node | Node et ses embeddings | _uuid, embedding_result |
algo(struc2vec).params({
walk_length: 10,
walk_num: 20,
k: 10,
stay_probability: 0.4,
window_size: 5,
dimension: 20,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}).stream() as embeddings
return embeddings