
Vous pouvez importer des données de diverses sources dans Ultipa Graph via le module Loader. Les sources de données prises en charge incluent CSV, JSON, JSONL, PostgreSQL, SQL Server, MySQL, BigQuery, Neo4j et Kafka.
Loader et Tâche
Dans ce module, vous pouvez créer des loaders, chacun contenant plusieurs tâches d'importation. Les tâches au sein d'un loader peuvent être exécutées individuellement ou simultanément (soit en série, soit en parallèle).
Créer un Loader
Cliquer sur le bouton New Loader sur la page principale de Loader créera un loader avec le nom par défaut My Loader.
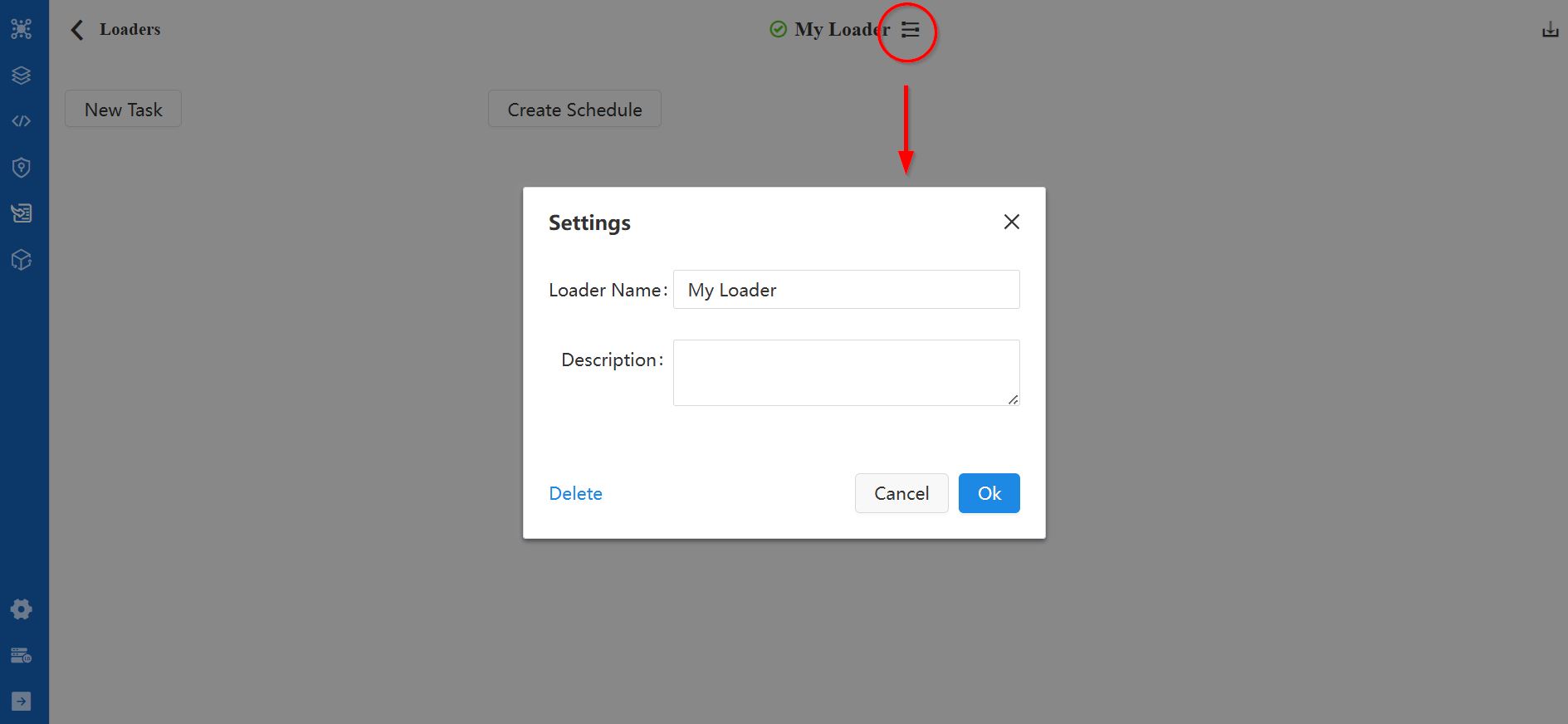
Sur la page de configuration du loader, vous pouvez renommer le loader et modifier sa description en cliquant sur l'icône située à côté du nom du loader.
Créer une Tâche
Pour ajouter une nouvelle tâche sur la page de configuration du loader, cliquez sur le bouton New Task et choisissez le type de source de données pour la tâche. Vous pouvez ajouter plusieurs tâches dans un loader.

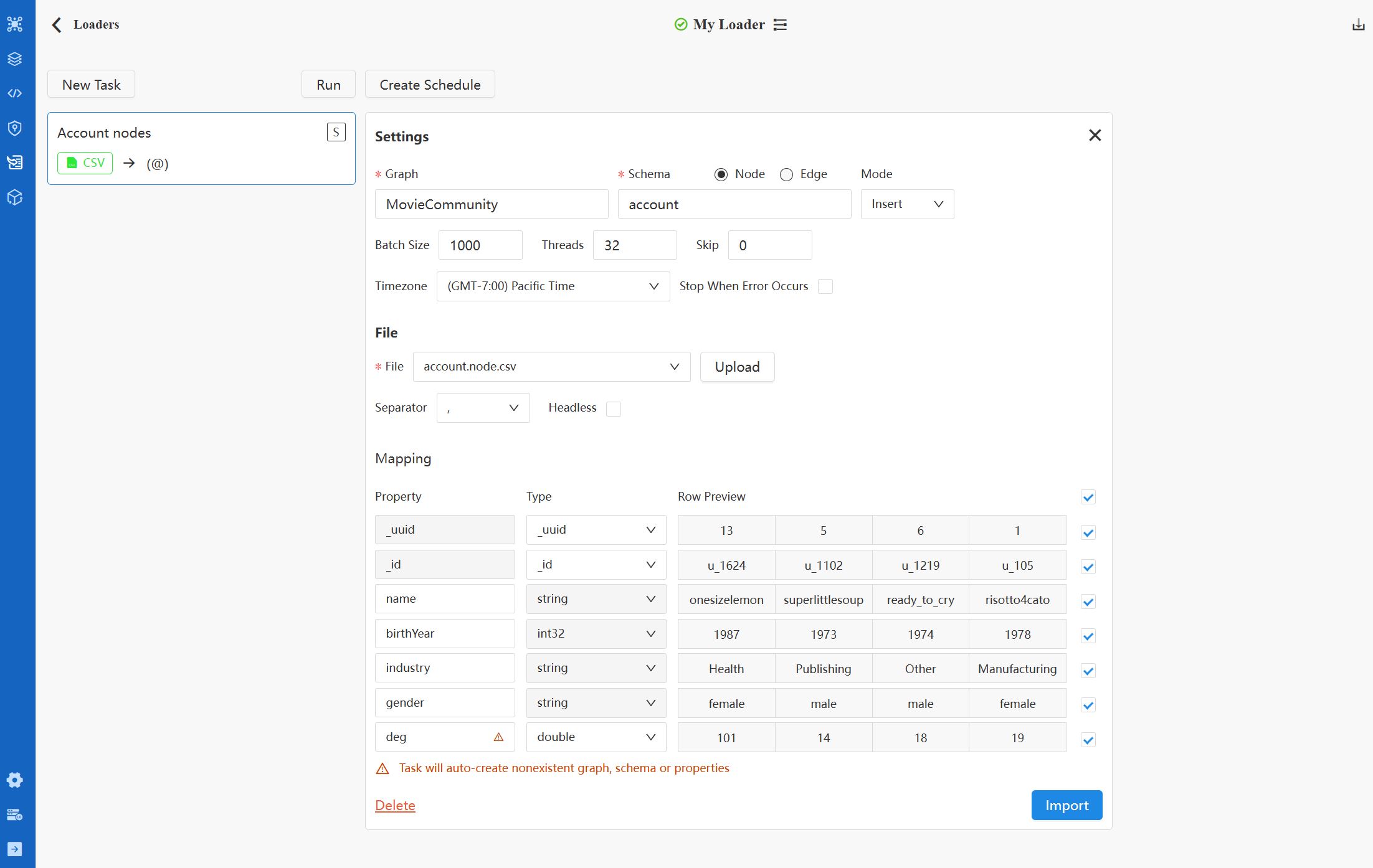
Vous pouvez définir le nom de la tâche en double-cliquant sur la zone correspondante sur la carte de tâche à gauche. Sur la droite se trouvent les configurations de la tâche. Veuillez vous référer à la Annexe : Configurations de Tâches pour plus de détails.
Importation
Importation de Tâche Unique
Cliquer sur le bouton Import dans une certaine tâche exécutera immédiatement la tâche.
Exécuter le Loader
Cliquer sur le bouton Run au-dessus de la liste des tâches déclenchera l'importation pour toutes les tâches dans le loader, en respectant l'ordre désigné et le mode de traitement :
- Les tâches sont exécutées de haut en bas. Vous pouvez réorganiser les tâches en faisant glisser et en déposant les cartes de tâche.
- Utilisez le tag
S/Psur chaque carte de tâche pour basculer entre les modes de traitement Serial (une après l'autre ; par défaut) et Parallel (simultané). - Les tâches
Padjacentes ainsi que la tâcheSprécédant immédiatement la première tâchePforment un groupe parallèle, importé simultanément.
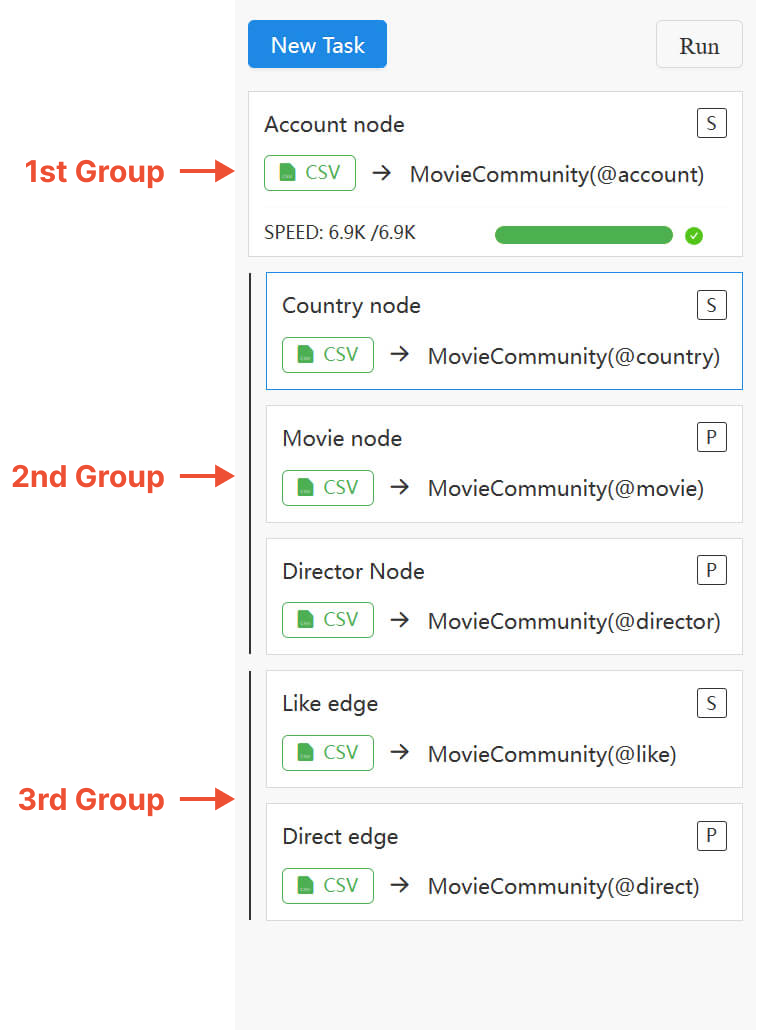
Des erreurs peuvent survenir lorsque vous importez des nodes et des edges simultanément, l'existence de nodes terminaux étant nécessaire pour la création des edges. Alternativement, envisagez d'importer les nodes avant les edges, ou assurez-vous de configurer correctement l'option Create Node If Not Exist et le mode d'importation Insert/Upsert/Overwrite.
Log d'Importation
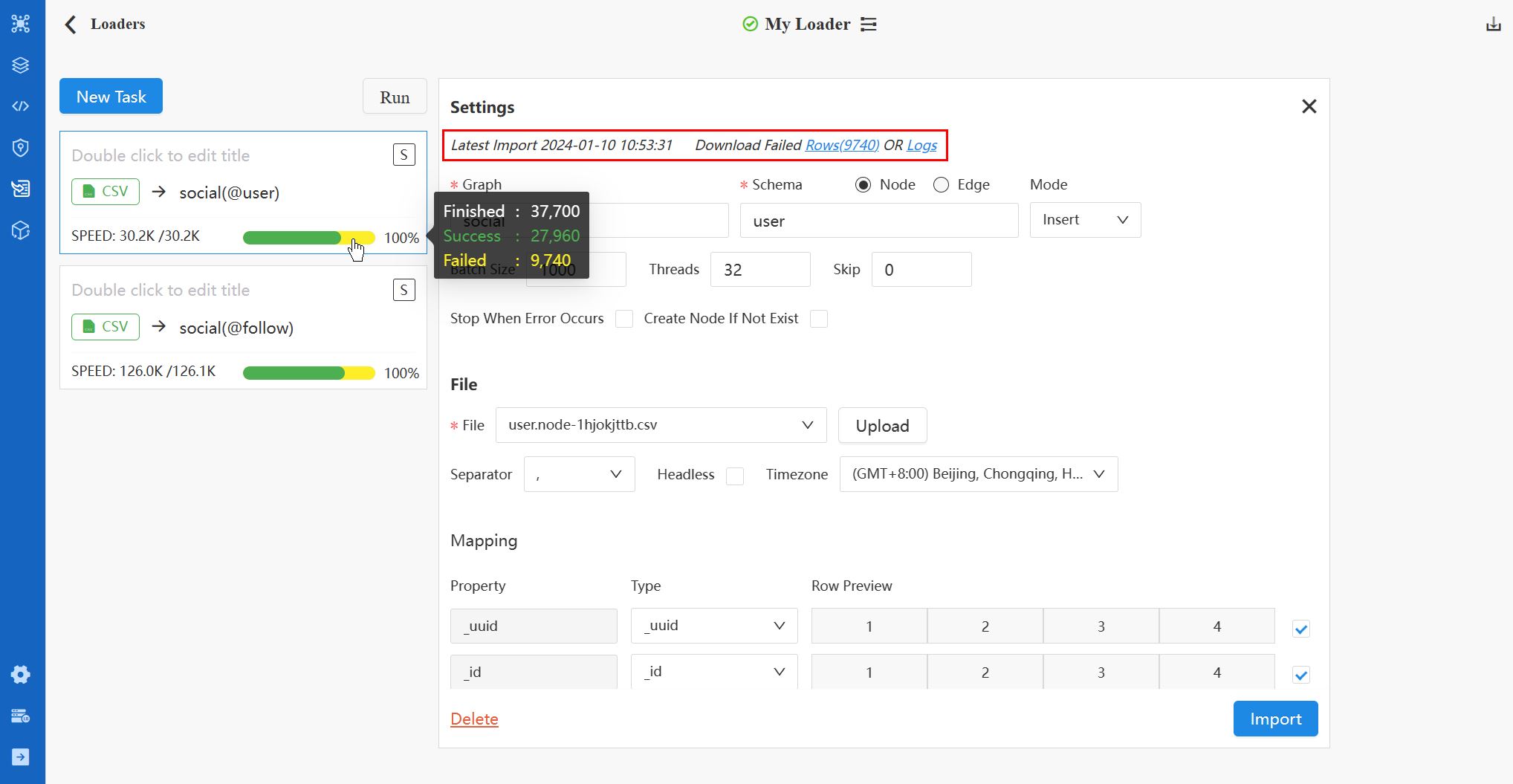
Typiquement, l'indicateur SPEED et la barre de process deviennent visibles sur la carte de tâche une fois l'importation commencée. Une importation réussie à 100 % est signalée par une barre de progression verte complète. Cependant, si des erreurs surviennent pendant la tâche, une partie de la barre de process devient jaune, reflétant le pourcentage de lignes de données échouées.
En haut du panneau de configuration à droite, le dernier log d'importation est affiché. Ici, vous pouvez télécharger les fichiers Failed Rows et Logs.
Importer/Exporter un Loader
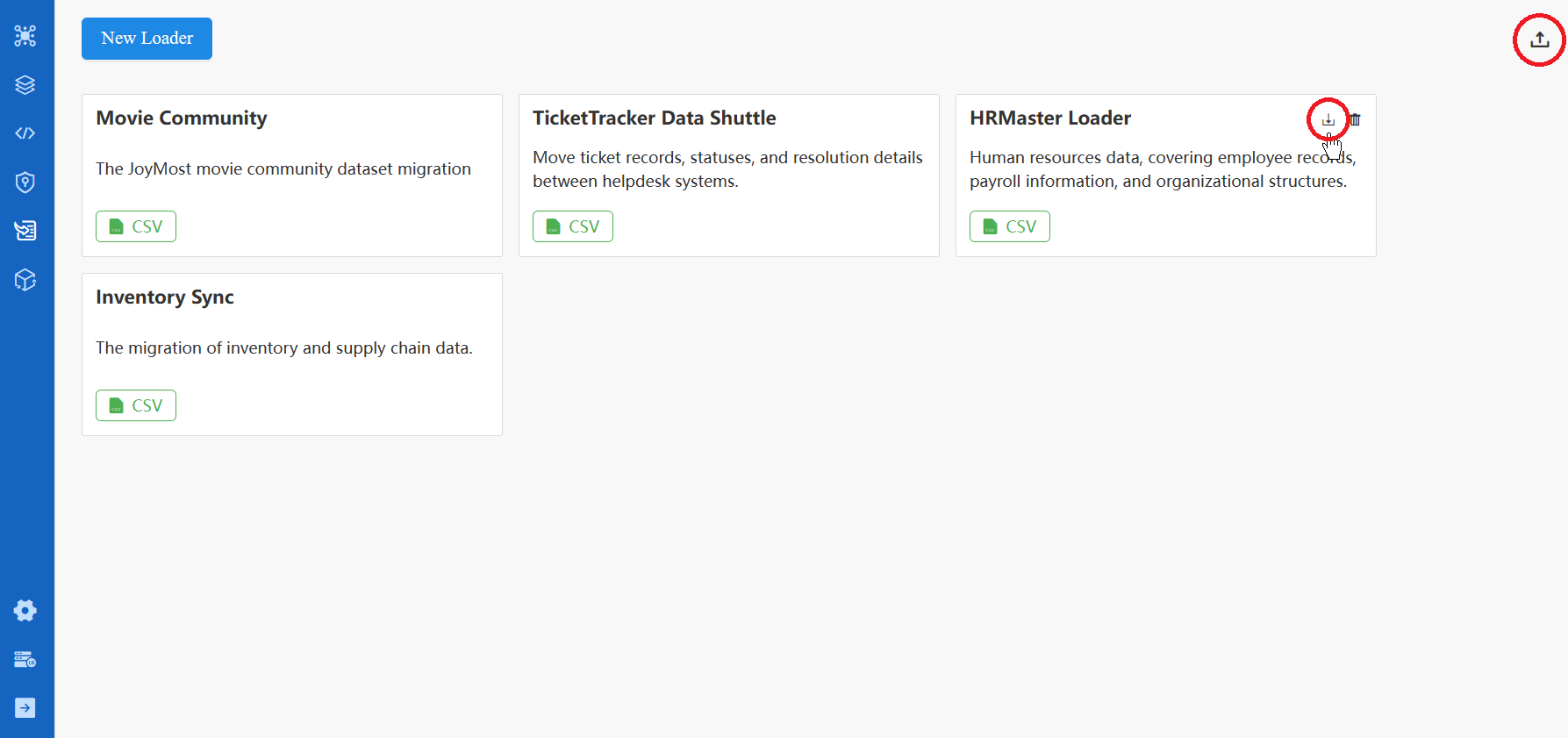
Vous pouvez exporter n'importe quel loader en tant que fichier ZIP depuis la carte de loader. L'option d'importer un loader est disponible en haut à droite de la page principale de Loader.
Annexe : Configurations de Tâches
Paramètres
Les configurations des tâches varient pour différentes sources de données. Cependant, la partie Settings est commune à toutes.
Élément |
Description |
|---|---|
| Graph | Choisissez un graph existant ou entrez le nom d'un nouveau graph. |
| Schema | Choisissez entre Node et Edge. Le champ Schema name ci-dessous se remplit avec les schémas correspondants pour le graph existant choisi. Si vous créez un nouveau graph, entrez manuellement le nom du schema. |
| Mode | Sélectionnez Insert, Upsert, ou Overwrite comme mode d'importation pour la tâche. |
| Batch Size | Définissez le nombre de lignes de données incluses dans chaque batch. |
| Threads | Définissez le nombre maximum de threads pour le process d'importation. |
| Skip | Définissez le nombre de lignes de données initiales à ignorer pendant le process d'importation. |
| Timezone | Sélectionnez le fuseau horaire pour convertir les horodatages en date et heure ; le défaut est le fuseau horaire de votre navigateur. |
| Stop When Error Occurs | Décidez si vous souhaitez arrêter le process d'importation en cas d'erreur. |
| Create Node If Not Exist | Décidez si vous souhaitez créer des nodes terminaux inexistants lors de l'importation des edges. Si non coché, les edges sans nodes terminaux existants ne seront pas importés et entraîneront des erreurs d'importation. Cette option est uniquement disponible pour la tâche d'importation des edges. |
Tout nouveau graph, schema, ou property est signalé par un marqueur d'avertissement, indiquant qu'ils seront créés pendant le process d'importation.
CSV
Fichier
Élément |
Description |
|---|---|
| File | Téléchargez un nouveau fichier CSV depuis la machine locale ou choisissez un fichier précédemment téléchargé. Vous pouvez supprimer les fichiers téléchargés de la liste déroulante. |
| Separator | Spécifiez le séparateur du fichier CSV : choisissez entre ,, ;, et |. |
| Headless | Indiquez si le fichier CSV commence par la ligne d'en-tête (fournissant les noms et types des properties) ou s'il est sans en-tête avec uniquement des lignes de données. |
Voici un exemple de fichier CSV pour des nodes @account, incluant un en-tête avec les noms et types des properties :
_id:_id,username:string,brithYear:int32
U001,risotto4cato,1978
U002,jibber-jabber,1989
U003,LondonEYE,1982
Voici un exemple de fichier CSV sans en-tête pour des edges @follow :
103,risotto4cato,jibber-jabber,1634962465
102,LondonEYE,jibber-jabber,1634962587
Mapping
Après avoir téléchargé ou sélectionné le fichier, la section de Mapping devient visible :
Élément |
Description |
|---|---|
| Property | Modifiez le nom de la property. Les champs sont remplis automatiquement si le fichier CSV a une en-tête fournissant les noms des properties. |
| Type | Choisissez le type de property. Les champs sont remplis automatiquement avec les types de property spécifiés dans la ligne d'en-tête du fichier CSV, ou ceux détectés en fonction des données. Si le nom de la property existe déjà sous le schema spécifié, le type ne peut pas être modifié. |
| Row Preview | Aperçu des 4 premières lignes de données. |
| Include/Ignore | Décochez la case pour ignorer la property pendant le process d'importation. |
JSON, JSONL
Fichier
Élément |
Description |
|---|---|
| File | Téléchargez un nouveau fichier JSON/JSONL depuis la machine locale ou choisissez un fichier précédemment téléchargé. Vous pouvez supprimer les fichiers téléchargés de la liste déroulante. |
Voici un exemple de fichier JSON pour des nodes @user :
[{
"_uuid": 1,
"_id": "U001",
"level": 2,
"registeredOn": "2018-12-1 10:20:23",
"tag": null
}, {
"_uuid": 2,
"_id": "U002",
"level": 3,
"registeredOn": "2018-12-1 12:45:12",
"tag": "cloud"
}]
Voici un exemple de fichier JSONL pour des nodes @user :
{"_uuid": 1, "_id": "U001", "level": 2, "registeredOn": "2018-12-1 10:20:23", "tag": null}
{"_uuid": 2, "_id": "U002", "level": 3, "registeredOn": "2018-12-1 12:45:12", "tag": "cloud"
}
Mapping
Après avoir téléchargé ou sélectionné le fichier, la section de Mapping devient visible :
Élément |
Description |
|---|---|
| Property | Modifiez le nom de la property. Les champs sont remplis automatiquement avec les clés dans le fichier. |
| Type | Choisissez le type de property. Si le nom de la property existe déjà sous le schema spécifié, le type ne peut pas être modifié. |
| Original | Les champs sont remplis automatiquement avec les clés dans le fichier. |
| Row Preview | Aperçu des 3 premières lignes de données. |
| Include/Ignore | Décochez la case pour ignorer la property pendant le process d'importation. |
PostgreSQL, SQL Server, MySQL
Base de Données Source
Élément |
Description |
|---|---|
| Host | L'adresse IP du serveur de la base de données. |
| Port | Le port du serveur de la base de données. |
| Database | Nom de la base de données à importer. |
| User | Nom d'utilisateur du serveur de la base de données. |
| Password | Mot de passe de l'utilisateur. |
| Test | Vérifiez si la connexion peut être établie avec succès. |
SQL
Écrivez la requête SQL pour récupérer les données de la base de données, puis cliquez sur Preview pour mapper les résultats aux properties des nodes ou des edges.
Voici un exemple de SQL pour retourner les colonnes name et registeredOn de la table users :
SELECT name, registeredOn FROM users;
Mapping
Une fois le SQL retourné, la section de Mapping devient visible :
Élément |
Description |
|---|---|
| Property | Modifiez le nom de la property. Les champs sont remplis automatiquement avec les noms de colonnes dans les résultats de la requête. |
| Type | Choisissez le type de property. Les champs sont remplis automatiquement avec le type de données de chaque colonne dans les résultats de la requête. Si le nom de la property existe déjà sous le schema spécifié, le type ne peut pas être modifié. |
| Original | Les champs sont remplis automatiquement avec les noms de colonnes dans les résultats de la requête. |
| Row Preview | Aperçu des 3 premières lignes de données. |
| Include/Ignore | Décochez la case pour ignorer la property pendant le process d'importation. |
BigQuery
Base de Données Source
Élément |
Description |
|---|---|
| Project ID | L'ID pour votre projet Google Cloud Platform. |
| Key (JSON) | La clé de compte de service, qui est un fichier JSON. Téléchargez un nouveau fichier JSON depuis la machine locale ou choisissez un fichier précédemment téléchargé. Vous pouvez supprimer les fichiers téléchargés de la liste déroulante. |
| Test | Vérifiez si la connexion peut être établie avec succès. |
SQL
Écrivez la requête SQL pour récupérer les données depuis BigQuery, puis cliquez sur Preview pour mapper les résultats aux properties des nodes ou des edges.
Voici un exemple de SQL pour retourner toutes les colonnes de la table users :
SELECT * FROM users;
Mapping
Une fois le SQL retourné, la section de Mapping devient visible :
Élément |
Description |
|---|---|
| Property | Modifiez le nom de la property. Les champs sont remplis automatiquement avec les noms de colonnes dans les résultats de la requête. |
| Type | Choisissez le type de property. Les champs sont remplis automatiquement avec le type de données de chaque colonne dans les résultats de la requête. Si le nom de la property existe déjà sous le schema spécifié, le type ne peut pas être modifié. |
| Original | Les champs sont remplis automatiquement avec les noms de colonnes dans les résultats de la requête. |
| Row Preview | Aperçu des 3 premières lignes de données. |
| Include/Ignore | Décochez la case pour ignorer la property pendant le process d'importation. |
Neo4j
Neo4j
Élément |
Description |
|---|---|
| Host | L'adresse IP du serveur de la base de données. |
| Port | Le port du serveur de la base de données. |
| Database | Nom de la base de données à importer. |
| User | Nom d'utilisateur du serveur de la base de données. |
| Password | Mot de passe de l'utilisateur. |
| Test | Vérifiez si la connexion peut être établie avec succès. |
Cypher
Écrivez la requête Cypher pour récupérer les nodes ou edges depuis Neo4j, puis cliquez sur Preview pour mapper les résultats aux properties des nodes ou des edges.
Voici un exemple de Cypher pour retourner tous les nodes avec le label user :
MATCH (n:user)
Mapping
Une fois que le Cypher retourne des résultats, la section de Mapping devient visible :
Élément |
Description |
|---|---|
| Property | Modifiez le nom de la property. Les champs sont remplis automatiquement avec les noms des properties dans les résultats de la requête. |
| Type | Choisissez le type de property. Les champs sont remplis automatiquement avec les types des properties dans les résultats de la requête. Si le nom de la property existe déjà sous le schema spécifié, le type ne peut pas être modifié. |
| Original | Les champs sont remplis automatiquement avec les noms des properties dans les résultats de la requête. |
| Row Preview | Aperçu des 3 premières lignes de données. |
| Include/Ignore | Décochez la case pour ignorer la property pendant le process d'importation. |
Kafka
Kafka
Élément |
Description |
|---|---|
| Host | L'adresse IP du serveur où le broker Kafka est en cours d'exécution. |
| Port | Le port sur lequel le broker Kafka écoute les connexions entrantes. |
| Topic | Le topic où les messages (données) sont publiés. |
| Offset | Sélectionnez le décalage pour spécifier quels messages vous souhaitez consommer (importer) : - Newest: Recevez les messages publiés après le démarrage du consommateur (tâche).- Oldest: Recevez tous les messages actuellement stockés dans le topic et les messages publiés après le démarrage du consommateur.- Since: Recevez les messages publiés après la date réglée et les messages publiés après le démarrage du consommateur.- Index: Recevez les messages dont les indexes sont égaux ou supérieurs à l'index réglé, et les messages publiés après le démarrage du consommateur. |
| Test | Vérifiez si la connexion peut être établie avec succès. |
| Preview | Mappez les messages récupérés aux properties des nodes ou des edges. |
Mapping
Une fois qu'il y a des messages retournés après avoir cliqué sur Preview, la section de Mapping devient visible :
Élément |
Description |
|---|---|
| Property | Modifiez le nom de la property. Les valeurs de property sont identifiées dans le contenu des messages par des virgules (,), et les noms de property par défaut sont col<N>. |
| Type | Choisissez le type de property. Si le nom de la property existe déjà sous le schema spécifié, le type ne peut pas être modifié. |
| Row Preview | Aperçu des 4 premières lignes de données. |
| Include/Ignore | Décochez la case pour ignorer la property pendant le process d'importation. |
La tâche Kafka (consommateur), une fois démarrée, continuera à fonctionner pour importer les messages nouvellement publiés. Vous devez arrêter manuellement la tâche selon les besoins.