
Vue d’ensemble
L'algorithme GraphSAGE Train est utilisé pour entraîner le modèle GraphSAGE. Le processus d'entraînement s'effectue dans un cadre entièrement non supervisé et implique l'utilisation de techniques telles que SGD et backpropagation.
Le modèle GraphSAGE entraîné peut être utilisé pour générer des embeddings de node. Ce cadre inductif est également capable de produire des embeddings pour de nouveaux nodes sans nécessiter un nouvel entraînement du modèle. Pour des informations détaillées sur l'utilisation du modèle GraphSAGE à cette fin, veuillez vous référer à l'algorithme GraphSAGE.
Concepts
GraphSAGE : Apprentissage des Paramètres
Selon l'algorithme de génération d'embedding (propagation avant) de GraphSAGE, nous devons ajuster les paramètres de K fonctions d'agrégation (notées AGGREGATEk) et K matrices de poids (notées Wk).
La fonction de perte est conçue pour encourager les nodes proches à avoir des embeddings similaires, tout en imposant que les embeddings des nodes disparates soient très distincts :
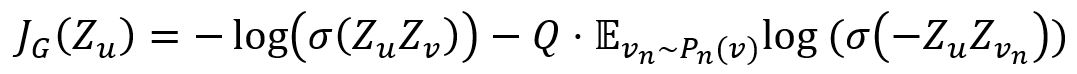
où,
- v est un node qui coexiste près de u sur un random walk de longueur fixe.
- vn est un échantillon négatif, Q est le nombre d'échantillons négatifs, Pn est la distribution de l'échantillonnage négatif.
- σ est la fonction sigmoïde.
- Z est l'embedding du node généré par le modèle GraphSAGE.
Dans les cas où les embeddings doivent être utilisés pour une tâche spécifique en aval, cette fonction de perte peut simplement être remplacée, ou augmentée, par un objectif spécifique à la tâche (par exemple, perte d'entropie croisée).
Fonctions d'Agrégation
Une fonction d'agrégation combine un ensemble de vecteurs en un seul vecteur, elle est utilisée pour produire le vecteur de voisinage dans GraphSAGE. Il existe deux types d'agrégateurs pris en charge.
1. Agrégateur de Moyenne
L'agrégateur de moyenne prend simplement la moyenne élément par élément des vecteurs. Par exemple, les vecteurs [1,2], [4,3] et [3,4] seront agrégés en vecteur [2.667,3].
Lorsqu'il est utilisé, l'algorithme de génération d'embeddings de GraphSAGE calcule directement l'embedding k-ème du node :
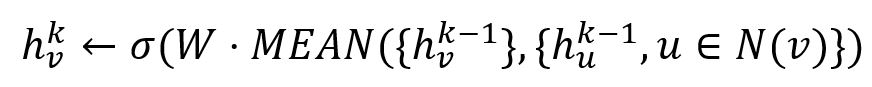
2. Agrégateur de Pooling
Dans l'approche par pooling, le vecteur de chaque voisin est alimenté indépendamment à travers un réseau neuronal entièrement connecté ; après cette transformation, une opération de max-pooling élément par élément est appliquée pour agréger les informations à travers l'ensemble des voisins :
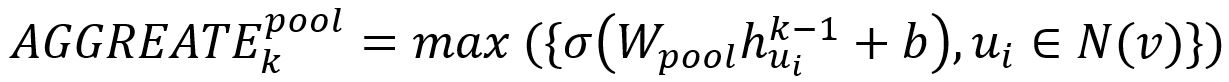
où max désigne l'opérateur max élément par élément et σ est une fonction d'activation non linéaire.
Considérations
- L'algorithme GraphSAGE Train ignore la direction des edges mais les calcule comme des edges non dirigés.
Syntaxe
- Commande :
algo(graph_sage_train) - Paramètres :
Nom |
Type |
Spécification |
Par Défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| dimension | entier | ≥2 | 64 |
Oui | Dimension des embeddings de node générés |
| node_property_names | []<property> |
Type numérique, doit être LTE | / | Non | Propriétés des nodes pour former les vecteurs de caractéristiques |
| edge_property_name | <property> |
Type numérique, doit être LTE | / | Oui | Propriété de edge à utiliser comme poids de edge ; les edges sont non pondérés si non définis |
| search_depth | entier | ≥1 | 5 |
Oui | Profondeur maximale du random walk |
| sample_size | []entier | / | [25, 10] |
Oui | Les éléments de la liste sont le nombre de nodes échantillonnés à la couche K à la couche 1 respectivement ; la taille de la liste est le nombre de couches |
| learning_rate | flottant | [0, 1] | 0.1 |
Oui | Taux d'apprentissage de chaque itération d'entraînement |
| epochs | entier | ≥1 | 10 |
Oui | Nombre de cycles d'entraînement importants ; l'échantillonnage du voisinage est refait pour chaque époque |
| max_iterations | entier | ≥1 | 10 |
Oui | Itérations d'entraînement maximales par époque ; chaque itération un lot est sélectionné au hasard pour calculer le gradient et mettre à jour les paramètres |
| tolerance | double | >0 | 1e-10 |
Oui | L'époque en cours se termine lorsque les valeurs de la fonction de perte entre les itérations sont inférieures à cette tolérance |
| aggregator | chaîne de caractères | mean, pool |
mean |
Oui | L'agrégateur à utiliser |
| batch_size | entier | ≥1 | Nombre de nodes/threads | Oui | Nombre de nodes par lot ; ceci est également utilisé comme le nombre d'échantillons négatifs |
Exemples
File Writeback
| Spécification | Contenu |
|---|---|
| model_name | Le modèle GraphSAGE entraîné |
algo(graph_sage_train).params({
dimension: 10,
node_property_names: ['dbField','fField','uInt32','int32','age'],
edge_property_name: 'rank',
search_depth: 5,
sample_size: [25,10],
learning_rate: 0.05,
epochs: 8,
max_iterations: 10,
tolerance: 1e-10,
aggregator: 'mean',
batch_size: 100
}).write({
file:{
model_name: 'SAGE_model'
}
})
Résultats : Fichier SAGE_model.json ; ce modèle peut être utilisé dans l'algorithme GraphSAGE pour générer des embeddings de node