
Vue d’ensemble
Le modèle Skip-gram de base est presque impraticable en raison de diverses exigences de calcul.
Les tailles des matrices et dépendent de la taille du vocabulaire (par exemple, ) et de la dimension de l'intégration (par exemple, ), où chaque matrice contient souvent des millions de poids (par exemple, millions) chacun ! Le réseau neuronal de Skip-gram devient ainsi très grand, nécessitant un nombre immense d'échantillons d'entraînement pour ajuster ces poids.
De plus, à chaque étape de rétropropagation, des mises à jour sont appliquées à tous les vecteurs de sortie () pour la matrice , bien que la plupart de ces vecteurs ne soient pas liés au mot cible et aux mots de contexte. Étant donné la taille importante de , ce processus de descente de gradient sera très lent.
Un autre coût important provient de la fonction Softmax, qui engage tous les mots dans le vocabulaire pour calculer le dénominateur utilisé pour la normalisation.
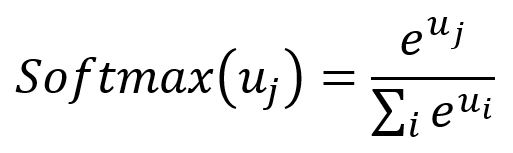
T. Mikoliv et d'autres ont introduit des techniques d'optimisation en conjonction avec le modèle Skip-gram, y compris sous-échantillonnage et échantillonnage négatif. Ces approches accélèrent non seulement le processus d'entraînement mais aussi améliorent la qualité des vecteurs d'intégration.
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, Distributed Representations of Words and Phrases and their Compositionality (2013)
- X. Rong, word2vec Parameter Learning Explained (2016)
Sous-échantillonnage
Les mots communs dans un corpus comme "the", "and", "is" posent certains problèmes :
- Ils ont une valeur sémantique limitée. Par exemple, le modèle bénéficie plus de la co-occurrence de "France" et "Paris" que de la co-occurrence fréquente de "France" et "the".
- Il y aura un excès d'échantillons d'entraînement contenant ces mots par rapport à la quantité nécessaire pour former les vecteurs correspondants.
L'approche de sous-échantillonnage est utilisée pour y remédier. Pour chaque mot du jeu d'entraînement, il y a une chance de le rejeter, et les mots moins fréquents sont rejetés moins souvent.
Tout d'abord, calculez la probabilité de conserver un mot par :
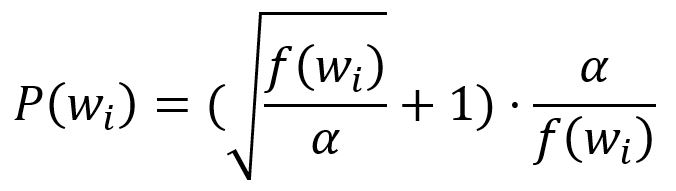
où est la fréquence du -ième mot, est un facteur qui influence la distribution et par défaut est à .
Ensuite, une fraction aléatoire entre et est générée. Si est plus petite que ce nombre, le mot est rejeté.
Par exemple, lorsque , alors pour , , donc les mots avec une fréquence de ou moins seront gardés à 100 %. Pour une fréquence de mot élevée comme , .
Dans le cas où , alors les mots avec une fréquence de ou moins seront gardés à 100 %. Pour la même fréquence de mot élevée , .
Ainsi, une valeur plus élevée de augmente la probabilité que les nodes fréquents soient sous-échantillonnés.
Par exemple, si le mot "a" est rejeté et n'est pas ajouté à la phrase d'entraînement "Graph is a good way to visualize data", les résultats d'échantillonnage pour cette phrase n'incluront aucun échantillon où "a" sert de mot cible ou de mot de contexte.
Échantillonnage négatif
Dans l'approche de l'échantillonnage négatif, lorsqu'un mot de contexte positif est échantillonné pour un mot cible, un total de mots est simultanément choisi comme échantillons négatifs.
Par exemple, considérons le corpus simple lors de la discussion du modèle Skip-gram de base. Ce corpus comprend un vocabulaire de 10 mots : graph, is, a, good, way, to, visualize, data, very, at. Lorsque l'échantillon positif (target, content): (is, a) est généré en utilisant une fenêtre glissante, nous sélectionnons mots négatifs graph, data et at pour l'accompagner :
| Mot Cible | Mot de Contexte | Sortie Attendue | |
|---|---|---|---|
| is | Échantillon Positif | a | 1 |
| Échantillons Négatifs | graph | 0 | |
| data | 0 | ||
| at | 0 |
Avec l'échantillonnage négatif, l'objectif d'entraînement du modèle passe de la prédiction des mots de contexte pour le mot cible à une tâche de classification binaire. Dans cette configuration, la sortie pour le mot positif est attendue comme , tandis que les sorties pour les mots négatifs sont attendues comme ; d'autres mots qui ne tombent dans aucune de ces catégories sont ignorés.
En conséquence, lors du processus de rétropropagation, le modèle met à jour uniquement les vecteurs de sortie associés aux mots positifs et négatifs pour améliorer la performance de classification du modèle.
Considérons le scénario où et . Lorsqu'on applique l'échantillonnage négatif avec le paramètre , seuls poids individuels dans nécessiteront des mises à jour, ce qui représente des millions de poids à mettre à jour sans échantillonnage négatif !
Nos expériences indiquent que les valeurs de dans la gamme sont utiles pour les petits ensembles de données d'entraînement, tandis que pour les grands ensembles de données, le peut être aussi petit que . (Mikolov et al.)
Une distribution probabiliste est nécessaire pour sélectionner les mots négatifs. Le principe fondamental est de privilégier les mots fréquents dans le corpus. Cependant, si la sélection est basée uniquement sur la fréquence des mots, elle peut entraîner une surreprésentation des mots à haute fréquence et une négligence des mots à basse fréquence. Pour remédier à ce déséquilibre, une distribution empirique est souvent utilisée impliquant l'élevation de la fréquence des mots à la puissance de :
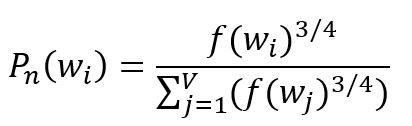
où est la fréquence du -ième mot, le souscript de indique le concept de bruit, la distribution est également appelée distribution de bruit.
Dans les cas extrêmes où le corpus contient seulement deux mots, avec des fréquences de et respectivement, l'utilisation de la formule ci-dessus donnerait des probabilités ajustées de et . Cet ajustement contribue dans une certaine mesure à atténuer le biais de sélection inhérent découlant des différences de fréquence.
Travailler avec des grands corpus peut poser des défis en termes d'efficacité computationnelle pour l'échantillonnage négatif. Par conséquent, nous adoptons en outre un paramètre resolution pour redimensionner la distribution de bruit. Une valeur plus élevée de resolution fournira une approximation plus proche de la distribution de bruit originale.
Entraînement du Modèle Optimisé
Propagation Avant
Nous allons démontrer avec le mot cible is, le mot positif a, et les mots négatifs graph, data et at:

Avec l'échantillonnage négatif, le modèle Skip-gram utilise la variation suivante de la fonction Softmax, qui est en réalité la fonction Sigmoid () de . Cette fonction mappe tous les composants de dans la plage de à :
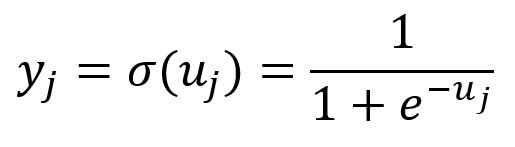
Rétropropagation
Comme expliqué, la sortie pour le mot positif, notée , est attendue à ; tandis que les sorties correspondant aux mots négatifs, notées , sont attendues à . Par conséquent, l'objectif de l'entraînement du modèle est de maximiser à la fois et , ce qui peut être interprété de manière équivalente comme maximisant leur produit:
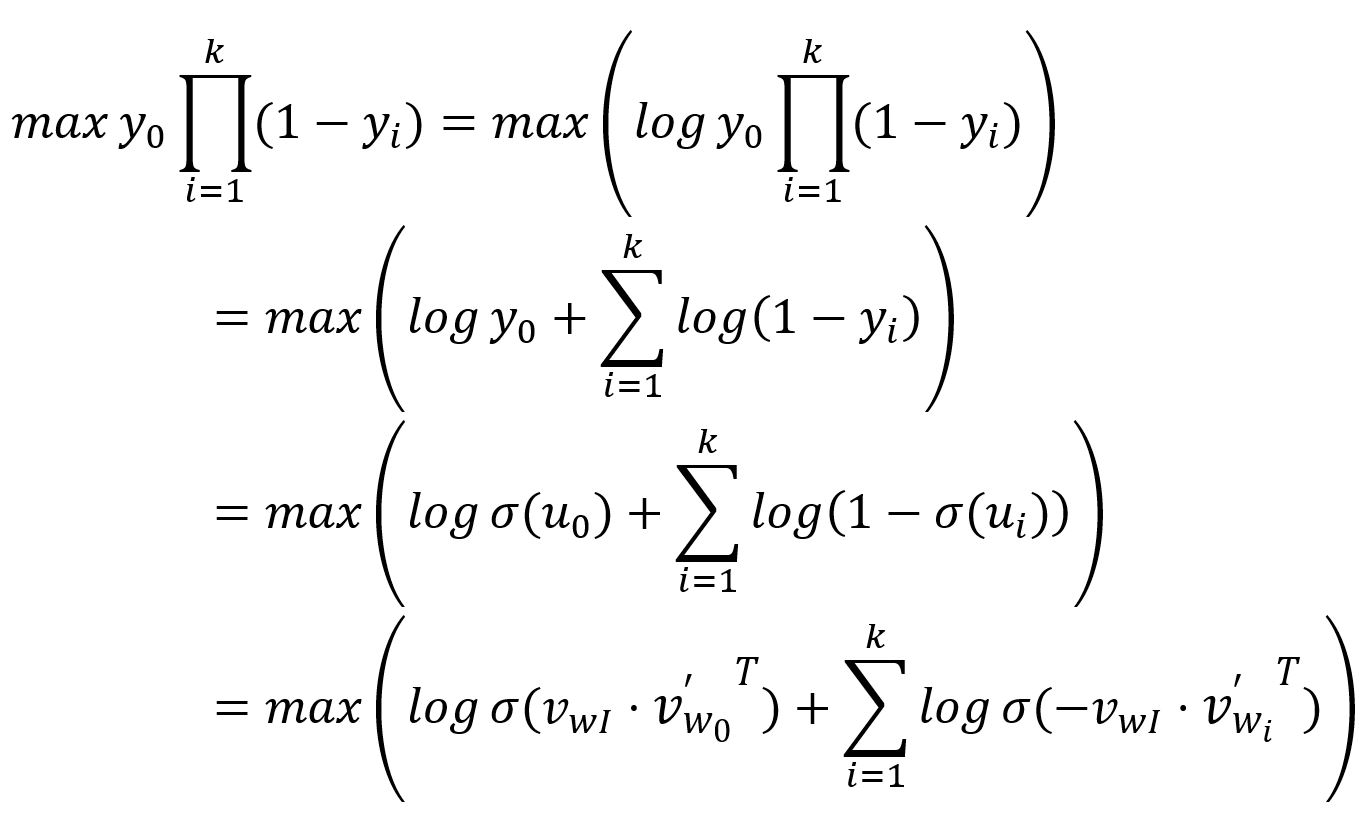
La fonction de perte est ensuite obtenue en transformant le dessus en un problème de minimisation:
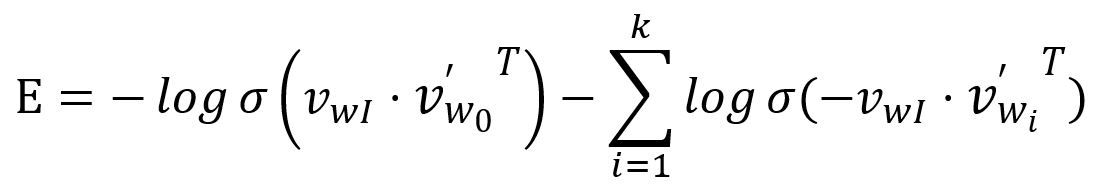
Prenez la dérivée partielle de par rapport à et :
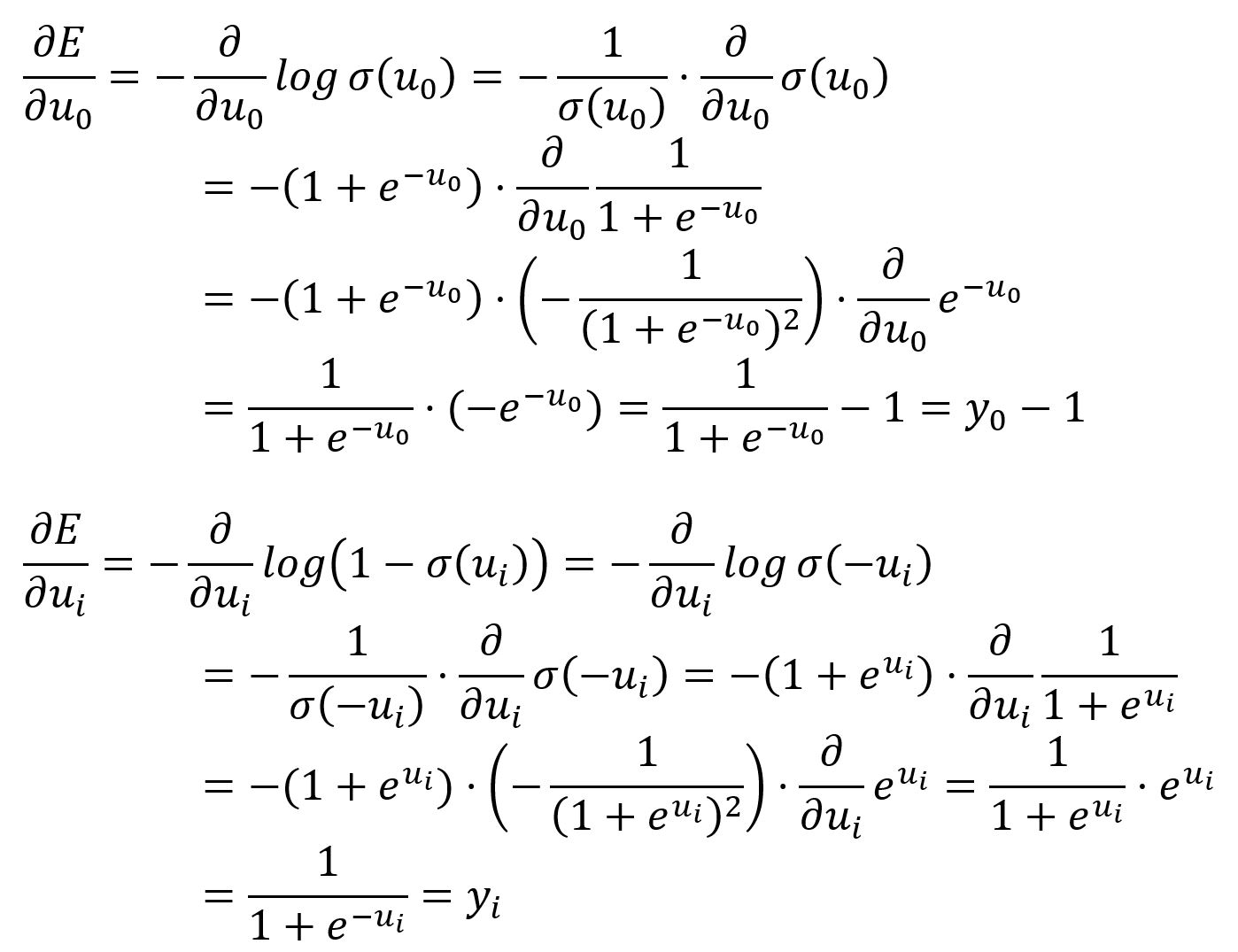
et ont une signification similaire à dans le modèle Skip-gram original, qui peut être compris comme soustrayant le vecteur attendu du vecteur de sortie:
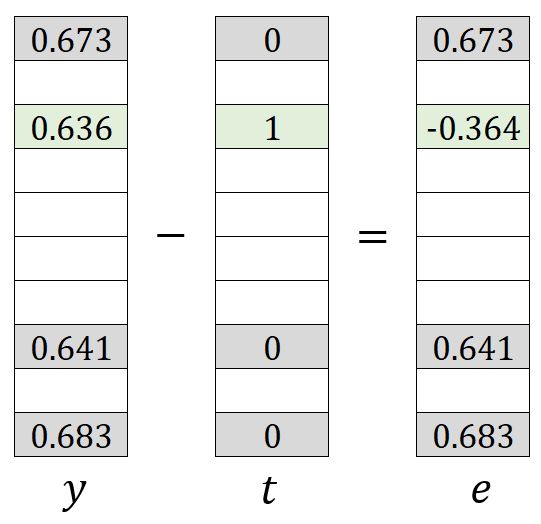
Le processus de mise à jour des poids dans les matrices et est simple. Vous pouvez vous référer à la forme originale de Skip-gram. Cependant, seuls les poids , , , , , , et dans et les poids et dans sont mis à jour.