
This page demonstrates the process of importing data from CSV file(s) into an Ultipa graphset.
Ultipa Transporter supports two methods for importing CSV data:
- Import from individual CSV files:
- No modification of the original files is required.
- Configure target schemas directly in the YAML file.
- No modification of the original files is required.
- Import from a folder:
- Modify original files to meet the required format.
- No configuration for each schema is needed in the YAML file.
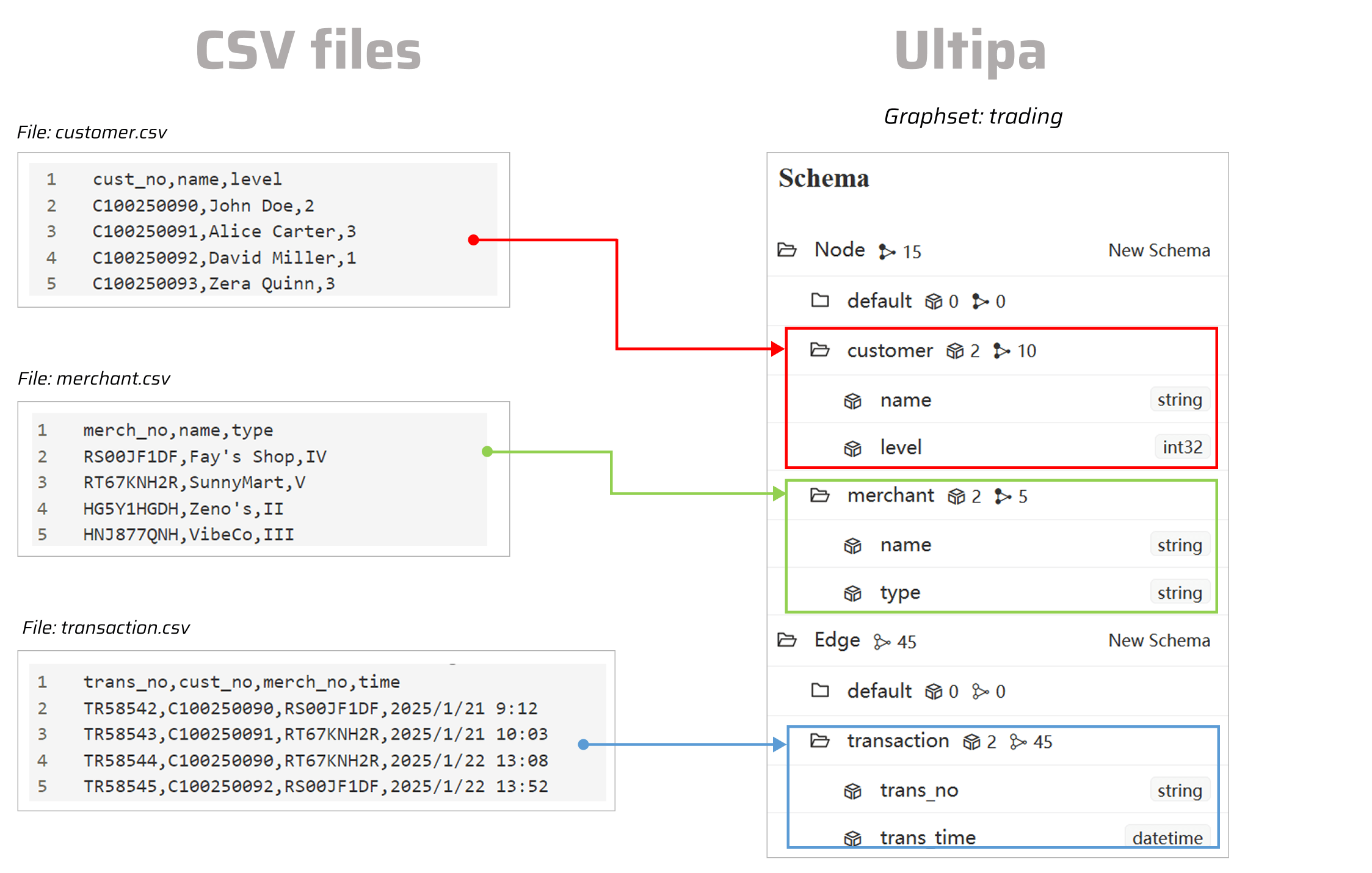
Import from CSV Files
Generate Configuration File
Execute the following command in your command line tool and select csv.
./ultipa-importer --sample
The import.sample.csv.yml file will be generated in the same directory as ultipa-importer.exe. If a import.sample.csv.yml file already exists in that directory, it will be overwritten.
Modify Configuration File
The configuration file consists of several sections. Modify the configuration file according to your needs.
If SFTP is not used, remove the section involving SFTP server configurations from the configuration file below.
# Mode options: csv/json/jsonl/rdf/graphml/bigQuery/sql/kafka/neo4j/salesforce; only one mode can be used
# SQL supports mysql/postgresSQL/sqlserver/snowflake/oracle
mode: csv
# Ultipa server configurations
server:
# Host IP/URI and port
# If it is a cluster, separate hosts with commas, i.e., "<ip1>:<port1>,<ip2>:<port2>,<ip3>:<port3>"
host: "10.11.22.33:1234"
username: "admin"
password: "admin12345"
# The new or existing graphset where data will be imported
graphset: "trading"
# If the above graphset is new, specify the shards where it will be stored
shards: "1,2,3"
# If the above graphset is new, specify the partition function (Crc32/Crc64WE/Crc64XZ/CityHash64) used for sharding
partitionBy: "Crc32"
# Path of the certificate file for TLS (optional)
crt: ""
# SFTP server configurations
sftp:
# Host IP/URI and port
host: "10.12.23.34:4567"
username: "yourUsername"
password: "yourPassword"
# SSH Key path for SFTP (if set, password will not be used)
key: "./my_secret"
# Node configurations
nodeConfig:
# Specify the node type (schema) that the imported nodes belong to
- schema: "customer"
# Specify the file path. If SFTP is configured, provide the SFTP path
file: "./dataset/trading/customer.csv"
# Specify whether the file includes a header
head: true
# properties: Map data to graph database properties
# For each property, you can configure the following:
## name: The column name from the CSV file
## new_name: The property name to which the column will be mapped; if unset, it defaults to the column name
## type: Supported types include _id, _from, _to, _ignore (to skip importing the column), and other Ultipa property types like int64, int32, float, string, etc.
## prefix: Add a prefix to the values of the _id, _from, or _to types; it does not apply to other types
# If properties are not configured, the system will automatically map them based on the csv file
# Columns mapped as _id, _uuid, _from, _from_uuid, _to, or _to_uuid in csv files must be explicitly configured
properties:
- name: cust_no
type: _id
- name: name
type: string
prefix: Test
- name: level
type: int32
- schema: "merchant"
file: "./dataset/trading/merchant.csv"
head: true
properties:
- name: merch_no
type: _id
- name: name
type: string
- name: type
type: string
# Edge configurations
edgeConfig:
- schema: "transaction"
file: "./dataset/trading/transaction.csv"
head: true
properties:
- name: trans_no
type: string
- name: cust_no
type: _from
- name: merch_no
type: _to
- name: time
new_name: trans_time
type: datetime
# Global settings
settings:
# Delimiter used for the CSV files (applicable only in the csv mode)
separator: ","
# Define the path to output the log file
logPath: "./logs"
# Number of rows included in each insertion batch
batchSize: 10000
# Import mode supports insert/overwrite/upsert
importMode: insert
# Automatically create missing end nodes for edges (applicable only when importing edges)
createNodeIfNotExist: false
# Stops the importing process when error occurs
stopWhenError: false
# When importing a headless CSV and the number of configured fields differs from the number of fields in the file, set to true to omit or auto-fill data fields based on the configuration (applicable only in the csv mode)
fitToHeader: true
# Set to true to automatically create missing graphset, schemas and properties
yes: true
# The maximum threads
threads: 32
# The maximum size (in MB) of each packet
maxPacketSize: 40
# Set how quotation marks (") are handled in CSV files:
## false(default): treats " as field delimiter
## true: treats " as part of the field value
quotes: false
# Timezone for the timestamp values
# timeZone: "+0200"
# Timestamp value unit, support ms/s
timestampUnit: s
Configuration Items
Ultipa server configurations
Field |
Type |
Description |
|---|---|---|
host |
String | IP address or URI of the source database. |
username |
String | Database username. |
password |
String | Password of the above user. |
graphset |
String | Name of the target graphset for CSV file import. If the specified graphset does not exist, it will be created automatically. |
shards |
String | Specifies the shards where data will be processed. |
partitionBy |
String | Specifies the patitioning algorithm, including Crc32, Crc64WE, Crc64XZ and CityHash64. |
crt |
String | Path to the certificate (CRT) file used for TLS encryption. |
SFTP server configurations
Field |
Type |
Description |
|---|---|---|
host |
String | IP address or URI of the SFTP server. |
username |
String | SFTP server username used for authentication. |
password |
String | Password of the above user. |
key |
String | Path to the SSH key for SFTP authentication. If set, the password will be ignored. |
Node/Edge configurations
Field |
Type |
Description |
|---|---|---|
schema |
String | The node type (schema) to which the imported nodes belong. |
file |
String | Path to the CSV file. |
head |
String | Specify whether the file includes a header. |
name |
String | name defines the property name. Ensure that the order of name entries matches the column order in the CSV file. |
type |
String | Specify the data type. See supported property value types. |
prefix |
String | Add a prefix to the data. This is only supported for data types including _id, _from, and _to. |
new_name |
String | Modify the property name specified in name to a new value. |
Global settings
Field |
Type |
Default |
Description |
|---|---|---|---|
separator |
String | , | Delimiter used for the CSV files (applicable only in the csv mode). |
logPath |
String | "./logs" | The path to save the log file. |
batchSize |
Integer | 10000 | Number of nodes or edges to insert per batch. |
importMode |
String | upsert | Specifies how the data is inserted into the graph, including overwrite, insert and upsert. When updating nodes or edges, use the upsert mode to prevent overwriting existing data. |
createNodeIfNotExist |
Bool | false | Whether missing nodes are automatically created when inserting edges:true: The system automatically creates nodes that do not exist.false: The related edges will not be imported. |
stopWhenError |
Bool | false | Whether to stop the import process when an error occurs. |
fitToHeader |
Bool | false | When importing a headerless CSV file, if the number of configured properties differs from the number of columns in the file: true: Omits or auto-fills data fields based on the configuration.false: Stops the import and throws an error. |
yes |
Bool | false | Whether to automatically create missing graphset, schemas and properties. |
threads |
Integer | 32 | The maximum number of threads. 32 is suggested. |
maxPacketSize |
Integer | 40 | The maximum size of data packets in MB that can be sent or received. |
quotes |
Bool | false | Specifies how quotation marks (") are handled in CSV files:true: Treats " as part of the field value.false: Treats " as the field delimiter. |
timestampUnit |
String | s | The unit of measurement for timestamp data. Supported units are ms (milliseconds) and s (seconds). |
Execute Import
The import process uses the configuration file specified by the -config parameter to import CSV data into the target server and display it in the Ultipa graph structure.
./ultipa-importer --config import.sample.csv.yml
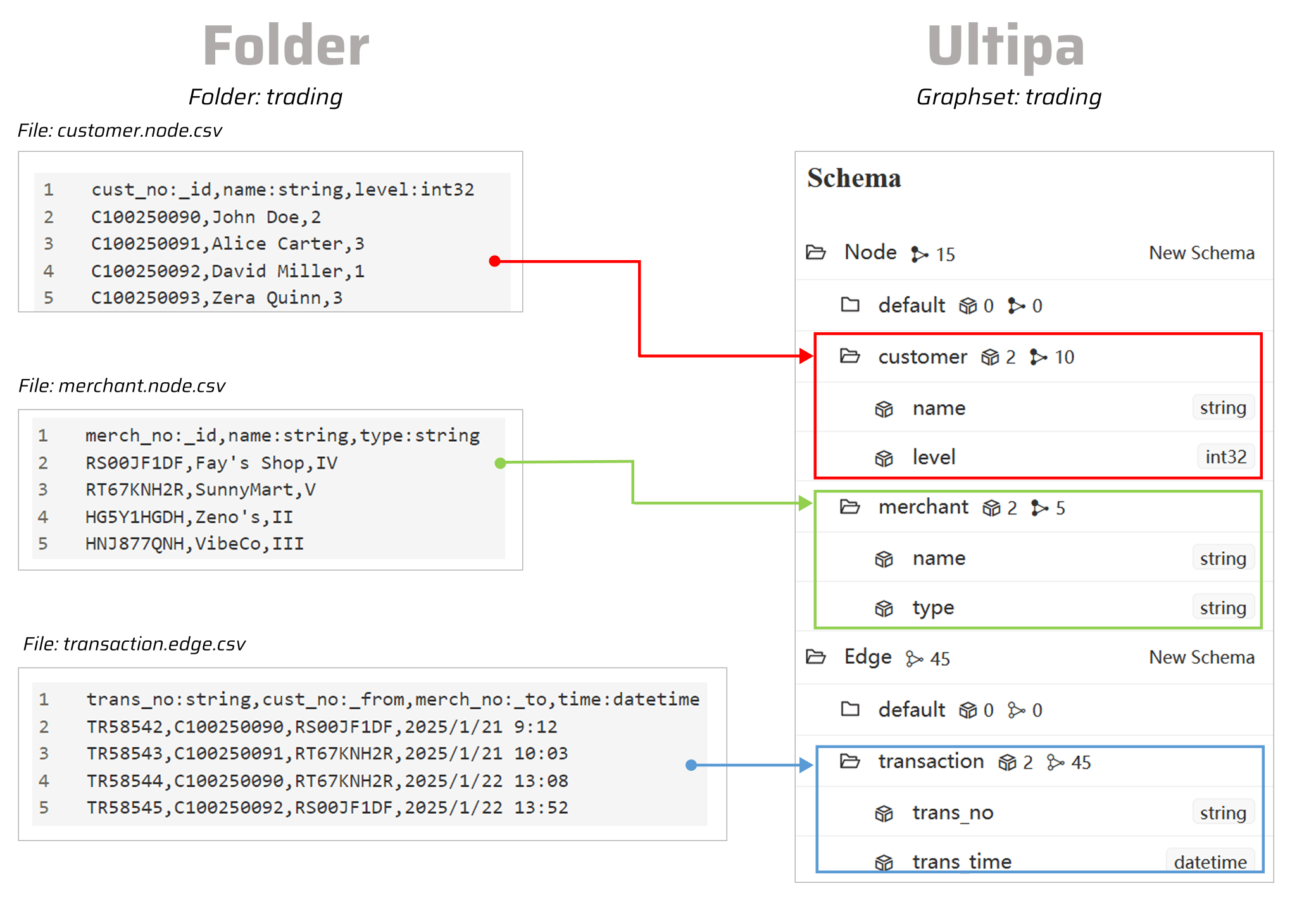
Import from a Folder
Modify CSV Files
Before importing data from a folder containing several CSV files, ensure that the file names and headers follow this format:
- File name:
- Use
<xxx>.node.csvor<xxx>.edge.csvto identify node and edge data.
- Use
- Header:
- All files must include headers in the format
<proName>:<type>.<proName>is the property name and is required.<type>represents the data type, and if not specified, it defaults to string. See supported property value types.
- For node data, find the column used as the unique identifier and name it
<anyName>:_id. - For edge data, find the columns for the source and destination nodes, and name them
<anyName>:_fromand<anyName>:_toseparately.
- All files must include headers in the format
Generate Configuration File
Execute the following command in your command line tool and select csv.
./ultipa-importer --sample
The import.sample.csv.yml file will be generated in the same directory as ultipa-importer.exe. If a import.sample.csv.yml file already exists in that directory, it will be overwritten.
Modify Configuration File
The configuration file consists of several sections. Modify the configuration file according to your needs.
If SFTP is not used, remove the section involving SFTP server configurations from the configuration file below.
# Mode options: csv/json/jsonl/rdf/graphml/bigQuery/sql/kafka/neo4j/salesforce; only one mode can be used
# SQL supports mysql/postgresSQL/sqlserver/snowflake/oracle
mode: csv
# Ultipa server configurations
server:
# Host IP/URI and port
# If it is a cluster, separate hosts with commas, i.e., "<ip1>:<port1>,<ip2>:<port2>,<ip3>:<port3>"
host: "10.11.22.33:1234"
username: "admin"
password: "admin12345"
# The new or existing graphset where data will be imported
graphset: "trading"
# If the above graphset is new, specify the shards where it will be stored
shards: "1,2,3"
# If the above graphset is new, specify the partition function (Crc32/Crc64WE/Crc64XZ/CityHash64) used for sharding
partitionBy: "Crc32"
# Path of the certificate file for TLS (optional)
crt: ""
# SFTP server configurations
sftp:
# Host IP/URI and port
host: "10.12.23.34:4567"
username: "yourUsername"
password: "yourPassword"
# SSH Key path for SFTP (if set, password will not be used)
key: "./my_secret"
# Node configurations
nodeConfig:
# Specify the folder path. If SFTP is configured, provide the SFTP path
- dir: "./dataset/trading"
# Edge configurations
edgeConfig:
- dir: "./dataset/trading"
# Global settings
settings:
# Delimiter used for the CSV files (applicable only in the csv mode)
separator: ","
# Define the path to output the log file
logPath: "./logs"
# Number of rows included in each insertion batch
batchSize: 10000
# Import mode supports insert/overwrite/upsert
importMode: insert
# Automatically create missing end nodes for edges (applicable only when importing edges)
createNodeIfNotExist: false
# Stops the importing process when error occurs
stopWhenError: false
# When importing a headless CSV and the number of configured fields differs from the number of fields in the file, set to true to omit or auto-fill data fields based on the configuration (applicable only in the csv mode)
fitToHeader: true
# Set to true to automatically create missing graphset, schemas and properties
yes: true
# The maximum threads
threads: 32
# The maximum size (in MB) of each packet
maxPacketSize: 40
# Set how quotation marks (") are handled in CSV files:
## false(default): treats " as field delimiter
## true: treats " as part of the field value
quotes: false
# Timezone for the timestamp values
# timeZone: "+0200"
# Timestamp value unit, support ms/s
timestampUnit: s
Configuration Items
Ultipa server configurations
Field |
Type |
Description |
|---|---|---|
host |
String | IP address or URI of the source database. |
username |
String | Database username. |
password |
String | Password of the above user. |
graphset |
String | Name of the target graphset for CSV file import. If the specified graphset does not exist, it will be created automatically. |
shards |
String | Specifies the shards where data will be processed. |
partitionBy |
String | Specifies the patitioning algorithm, including Crc32, Crc64WE, Crc64XZ and CityHash64. |
crt |
String | Path to the certificate (CRT) file used for TLS encryption. |
SFTP server configurations
Field |
Type |
Description |
|---|---|---|
host |
String | IP address or URI of the SFTP server. |
username |
String | SFTP server username used for authentication. |
password |
String | Password of the above user. |
key |
String | Path to the SSH key for SFTP authentication. If set, the password will be ignored. |
Node/Edge configurations
Field |
Type |
Description |
|---|---|---|
dir |
String | Path to the folder. |
Global settings
Field |
Type |
Default |
Description |
|---|---|---|---|
separator |
String | , | Delimiter used for the CSV files (applicable only in the csv mode). |
logPath |
String | "./logs" | The path to save the log file. |
batchSize |
Integer | 10000 | Number of nodes or edges to insert per batch. |
importMode |
String | upsert | Specifies how the data is inserted into the graph, including overwrite, insert and upsert. When updating nodes or edges, use the upsert mode to prevent overwriting existing data. |
createNodeIfNotExist |
Bool | false | Whether missing nodes are automatically created when inserting edges:true: The system automatically creates nodes that do not exist.false: The related edges will not be imported. |
stopWhenError |
Bool | false | Whether to stop the import process when an error occurs. |
fitToHeader |
Bool | false | When importing a headerless CSV file, if the number of configured properties differs from the number of columns in the file: true: Omits or auto-fills data fields based on the configuration.false: Stops the import and throws an error. |
yes |
Bool | false | Whether to automatically create missing graphset, schemas and properties. |
threads |
Integer | 32 | The maximum number of threads. 32 is suggested. |
maxPacketSize |
Integer | 40 | The maximum size of data packets in MB that can be sent or received. |
quotes |
Bool | false | Specifies how quotation marks (") are handled in CSV files:true: Treats " as part of the field value.false: Treats " as the field delimiter. |
timestampUnit |
String | s | The unit of measurement for timestamp data. Supported units are ms (milliseconds) and s (seconds). |
Execute Import
The import process uses the configuration file specified by the -config parameter to import CSV data into the target server and display it in the Ultipa graph structure.
./ultipa-importer --config import.sample.csv.yml