
This page demonstrates the process of importing data from Kafka topic(s) into an Ultipa graphset.
Generate Configuration File
Execute the following command in your command line tool and select kafka.
./ultipa-importer --sample
The import.sample.kakfka.yml file will be generated in the same directory as ultipa-importer.exe. If a import.sample.kafka.yml file already exists in that directory, it will be overwritten.
Modify Configuration File
The configuration file consists of several sections. Modify the configuration file according to your needs.
# Mode options: csv/json/jsonl/rdf/graphml/bigQuery/sql/kafka/neo4j/salesforce; only one mode can be used
# SQL supports mysql/postgresSQL/sqlserver/snowflake/oracle
mode: kafka
# Kafka host configurations
kafka:
# Host IP/URI and port
host: "192.168.1.23:4567"
# Ultipa server configurations
server:
# Host IP/URI and port
# If it is a cluster, separate hosts with commas, i.e., "<ip1>:<port1>,<ip2>:<port2>,<ip3>:<port3>"
host: "10.11.22.33:1234"
username: "admin"
password: "admin12345"
# The new or existing graphset where data will be imported
graphset: "trading"
# If the above graphset is new, specify the shards where it will be stored
shards: "1,2,3"
# If the above graphset is new, specify the partition function (Crc32/Crc64WE/Crc64XZ/CityHash64) used for sharding
partitionBy: "Crc32"
# Path of the certificate file for TLS (optional)
crt: ""
# Node configurations
nodeConfig:
# Specify the node type (schema) that the imported nodes belong to in Ultipa
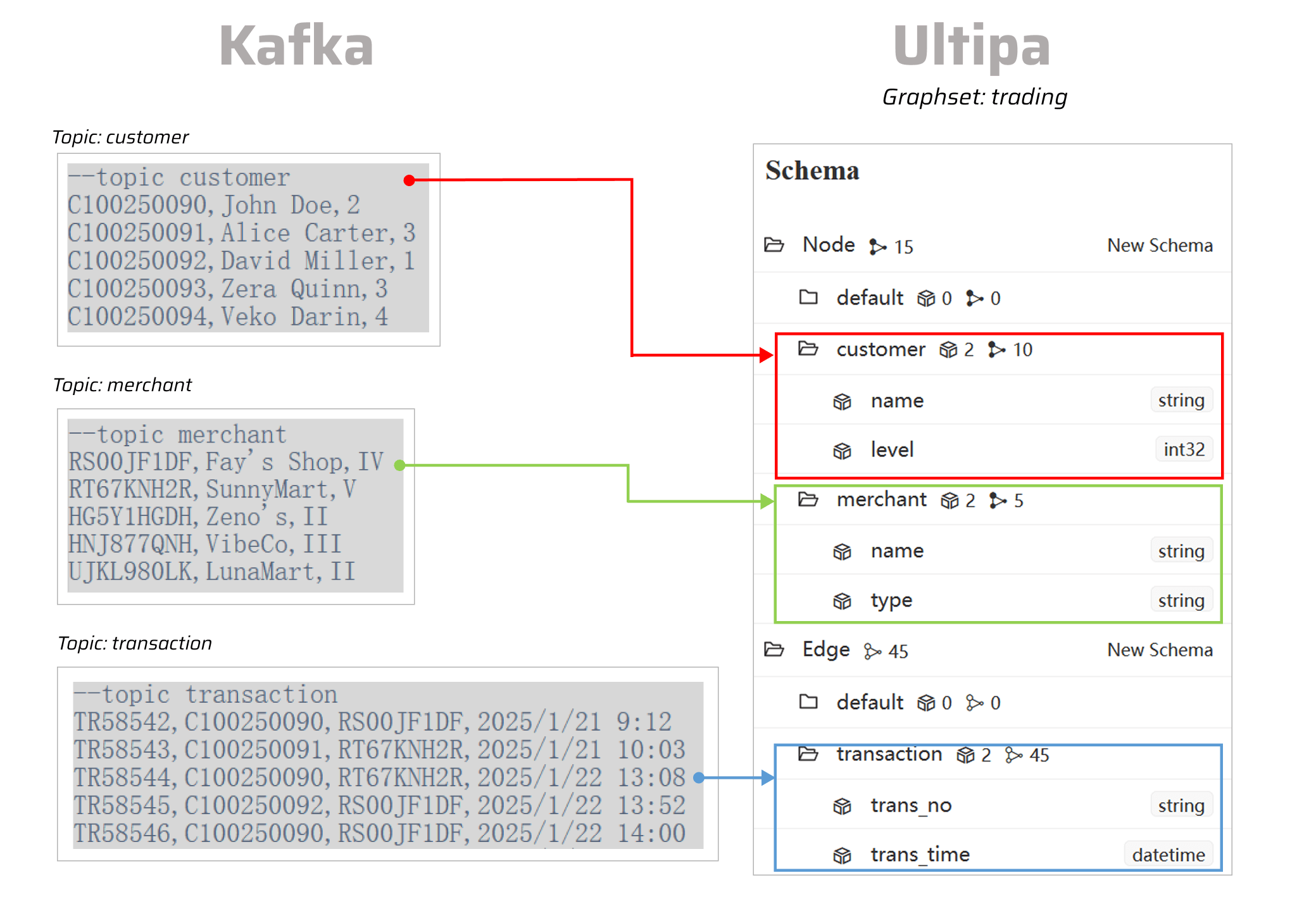
- schema: "customer"
# Specify the topic from which messages will be consumed
topic: "customer"
# offset: Specify where to start consuming messages in a Kafka topic partition
# options include:
## - newest: Start consuming from the latest available message
## - oldest(default): Start consuming from the earliest available message
## - index: Start consuming from a specific index/offset, e.g. offset: 5
## - time: Start consuming after a certain timestamp. The format is yyyy-mm-dd hh:mm:ss (local time) or yyyy-mm-dd hh:mm:ss -7000 (with time zone offset)
# For large kafka topics, it is more efficient to use newest, oldest or a specified index than a timestamp
offset: oldest
# properties: Map kafka messages to Ultipa graph database properties
# For each property, you can configure the following:
## name: The property name to use in Ultipa graph database
## new_name: The property name to use in Ultipa graph database; if unset, it defaults to the column name
## type: Supported types include _id, _from, _to, _ignore (to skip importing the column), and other Ultipa property types like int64, int32, float, string, etc.
## prefix: Add a prefix to the values of the _id, _from, or _to types; it does not apply to other types
# Columns mapped to system properties such as _id, _from or _to in kafka messages must be explicitly configured
properties:
- name: cust_no
type: _id
- name: name
type: string
- name: level
type: int32
- schema: "merchant"
topic: "merchant"
offset: oldest
properties:
- name: merch_no
type: _id
- name: name
type: string
- name: type
type: string
# Edge configurations
edgeConfig:
- schema: "transaction"
topic: "transaction"
offset: oldest
properties:
- name: trans_no
type: string
- name: cust_no
type: _from
- name: merch_no
type: _to
- name: trans_time
type: datetime
# Global settings
settings:
# Define the path to output the log file
logPath: "./logs"
# Number of rows included in each insertion batch
batchSize: 10000
# Import mode supports insert/overwrite/upsert
importMode: insert
# Automatically create missing end nodes for edges (applicable only when importing edges)
createNodeIfNotExist: false
# Stops the importing process when error occurs
stopWhenError: false
# Set to true to automatically create missing graphset, schemas and properties
yes: true
# The maximum threads
threads: 32
# The maximum size (in MB) of each packet
maxPacketSize: 40
# Timezone for the timestamp values
# timeZone: "+0200"
# Timestamp value unit, support ms/s
timestampUnit: s h
Configuration Items
Kafka host configurations
Field |
Type |
Description |
|---|---|---|
host |
String | IP address or URI of the Kafka broker. |
Ultipa server configuration
Field |
Type |
Description |
|---|---|---|
host |
String | IP address or URI of the source database. |
username |
String | Database username. |
password |
String | Password of the above user. |
graphset |
String | Name of the target graphset. If the specified graphset does not exist, it will be created automatically. |
shards |
String | Specifies the shards where data will be processed. |
partitionBy |
String | Specifies the patitioning algorithm, including Crc32, Crc64WE, Crc64XZ and CityHash64. |
crt |
String | Path to the certificate (CRT) file used for TLS encryption. |
Node/Edge configurations
Field |
Type |
Description |
|---|---|---|
schema |
String | The node type (schema) to which the imported nodes belong. |
topic |
String | The node type (topic) to which the imported messages belong. |
offset |
String | The unique identifier of a message within a Kafka partition. It supports: - newest: Start consuming from the latest available message.- oldest: Start consuming from the earliest available message. Default value.- index: Start consuming from a specific index/offset, e.g. offset: 5.- time: Start consuming after a certain timestamp. The format is yyyy-mm-dd hh:mm:ss (local time) or yyyy-mm-dd hh:mm:ss -7000 (with time zone offset). |
name |
String | The property name to use in target graph database. |
type |
String | Specify the data type. Use _ignore to skip importing the column. See supported property value types. |
prefix |
String | Add a prefix to the data. This is only supported for data types including _id, _from, and _to. |
new_name |
String | Modify the property name specified in name to a new value. |
Global settings
Field |
Type |
Default |
Description |
|---|---|---|---|
logPath |
String | "./logs" | The path to save the log file. |
batchSize |
Integer | 10000 | Number of nodes or edges to insert per batch. |
importMode |
String | upsert | Specifies how the data is inserted into the graph, including overwrite, insert and upsert. When updating nodes or edges, use the upsert mode to prevent overwriting existing data. |
createNodeIfNotExist |
Bool | false | Whether missing nodes are automatically created when inserting edges:true: The system automatically creates nodes that do not exist.false: The related edges will not be imported. |
stopWhenError |
Bool | false | Whether to stop the import process when an error occurs. |
yes |
Bool | false | Whether to automatically create missing graphset, schemas and properties. |
threads |
Integer | 32 | The maximum number of threads. 32 is suggested. |
maxPacketSize |
Integer | 40 | The maximum size of data packets in MB that can be sent or received. |
timestampUnit |
String | s | The unit of measurement for timestamp data. Supported units are ms (milliseconds) and s (seconds). |
Execute Import
The import process uses the configuration file specified by the -config parameter to import data from the kafka topics into the target server and display it in the Ultipa graph structure.
./ultipa-importer --config import.sample.kafka.yml